StrongBox V2: Engineering Design Document : From Bash Prototype to Production-Ready Secrets Infrastructure
A V1 architecture autopsy, three fully-designed new features, and a complete production readiness blueprint for a distributed secrets manager
Context
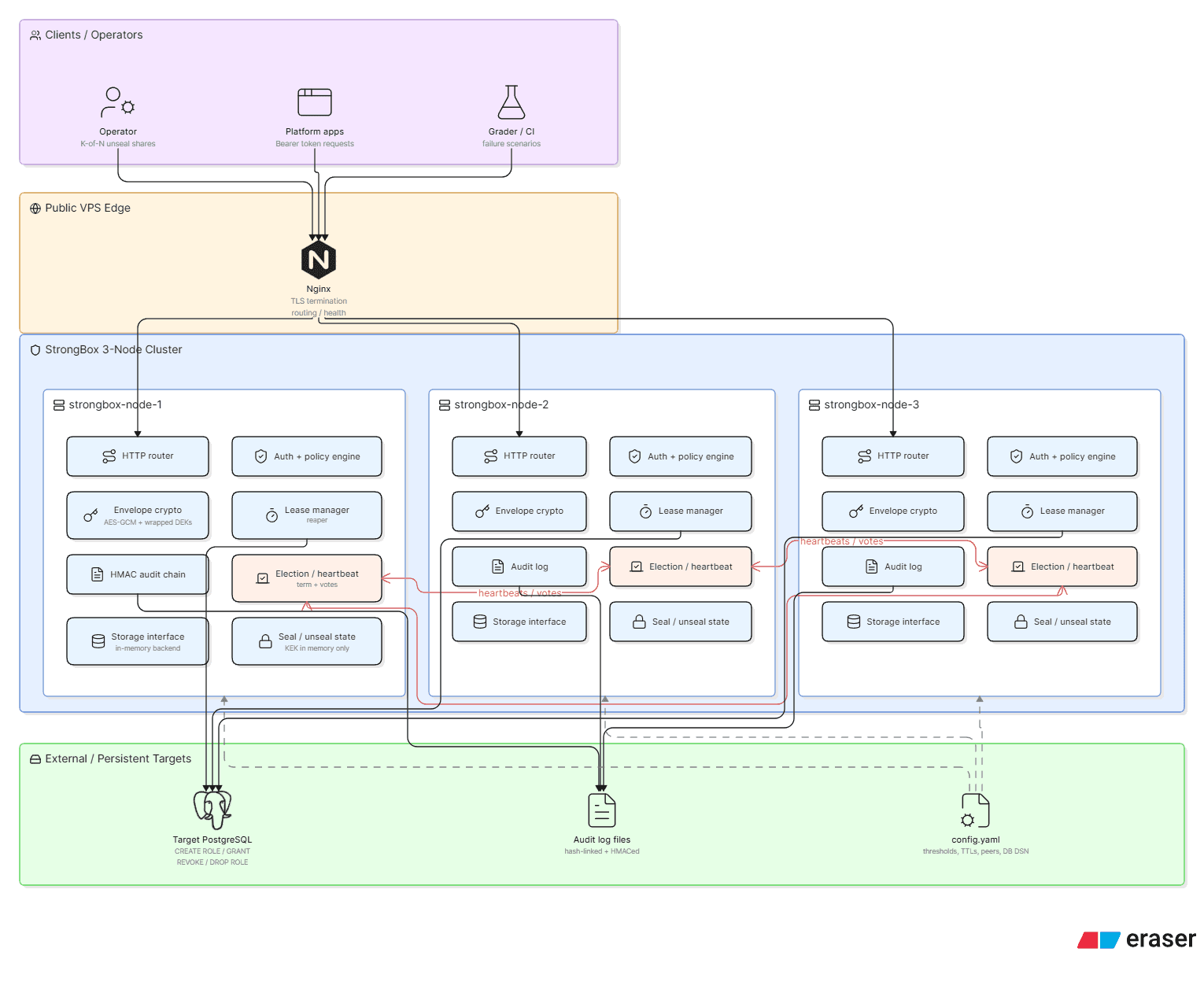
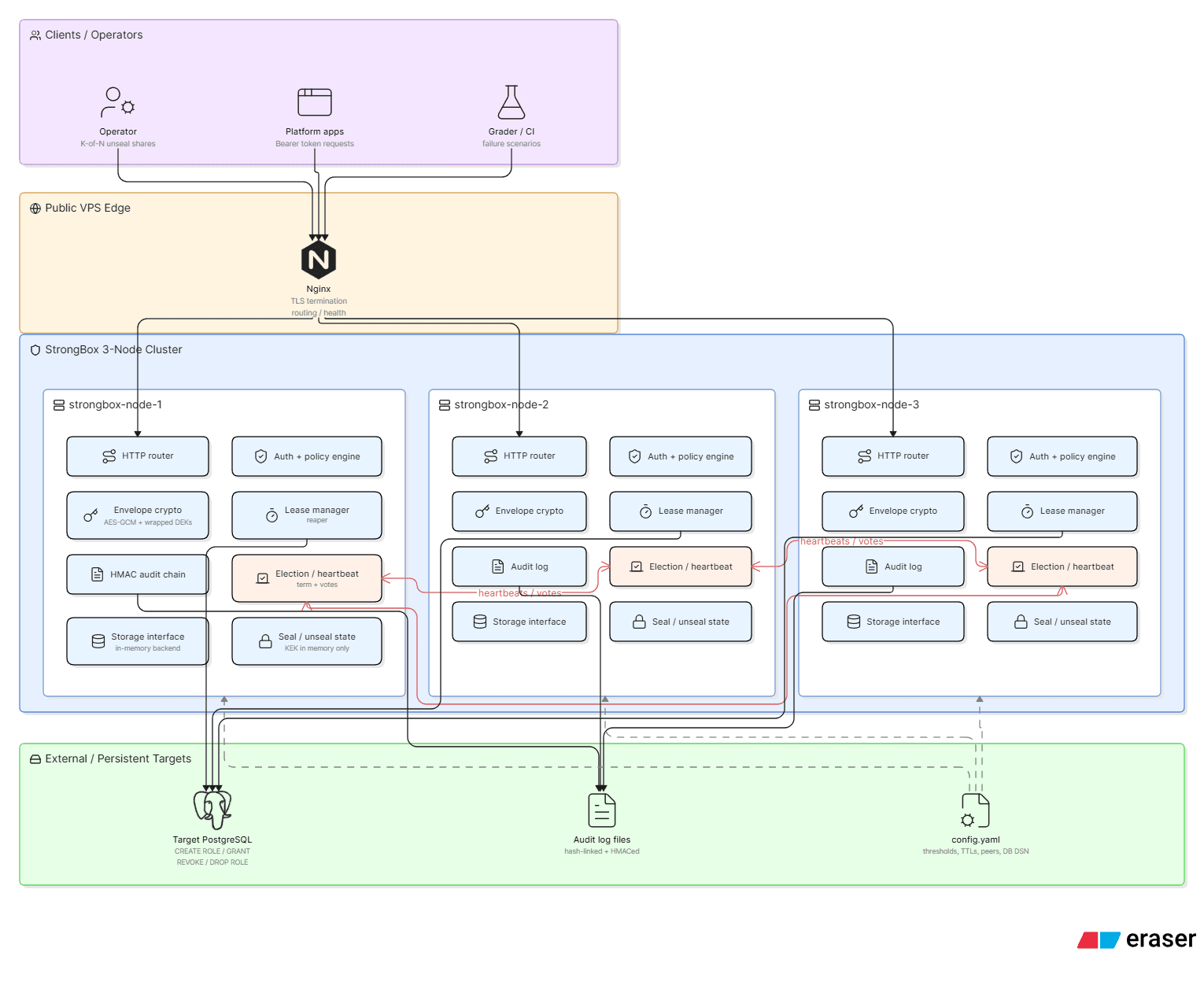
StrongBox V1 is a distributed secrets manager built entirely in Bash. It runs as a 3-node cluster behind Nginx TLS, uses ncat as an HTTP server (one forked process per TCP connection), stores all state on tmpfs, implements a hand-rolled Raft-inspired leader election, supports envelope-encrypted secrets, and generates short-lived PostgreSQL credentials via a dynamic secrets engine. /
It worked. It passed all 20 grading checks. It is also, by any reasonable production standard, a prototype that would fall apart under real traffic within minutes.
This document designs V2, the production-ready, horizontally scalable, observable, and defensible evolution.
Section 1: V1 Architecture Critique
The V1 System in One Paragraph
Three Ubuntu 24.04 Docker containers run a Bash parent process (bin/strongbox) that spawns ncat -l -k as a TCP listener. Every incoming connection causes ncat to fork a new subprocess running bin/http-handler, which sources approximately 1,000 lines of shell library code, handles exactly one HTTP request, and exits. Application state — secrets, tokens, policies, leases, and consensus metadata — lives in /dev/shm (RAM-backed tmpfs). A PostgreSQL instance handles only dynamic credential provisioning. Nginx provides TLS termination and blocks access to internal cluster routes.
Breaking Points
1. The fork-per-request model is a load time bomb.
Every request incurs the full cost of a Bash process fork plus sourcing 9 library modules. At idle on a VPS, measured round-trip latency was 300–800ms before any application logic ran. Under concurrent load this becomes a fork storm — the OS scheduler is overwhelmed not by application work but by process spawning. There is no connection keep-alive, no request pipelining, no connection pool. A realistic load of 100 requests/second would require 100 simultaneous Bash processes, each consuming ~20MB of virtual address space. This is not a performance concern — it is a structural ceiling.
2. tmpfs state means every restart is a full re-initialization.
All secrets, tokens, policies, leases, and consensus term/vote data live in /dev/shm/strongbox. A container restart, OOM kill, or node replacement wipes the entire vault state. Operators must re-submit Shamir shares, recreate all tokens, and recreate all policies from scratch. There is no persistence beyond the audit log (append-only to a Docker volume) and a sealed sentinel file. This is a deliberate trade-off (secrets never touch persistent disk) that was not accompanied by an operational procedure for safe cluster restarts.
3. Replication is fire-and-forget with no delivery guarantee.
The leader pushes writes to followers via POST /internal/replicate with no acknowledgment, no retry on failure, and no sequence number. If a follower is mid-restart when a write occurs, it silently misses it. There is no concept of a replication lag or a divergence detector. The cluster presents as healthy (/v1/sys/health returns 200 on all nodes) even when followers are multiple writes behind the leader.
4. The Raft implementation handles elections but not log replication.
The hand-rolled consensus layer (lib/consensus.sh) implements term-based leader election, randomized election timeouts, and quorum-enforced write gating. What it does not implement: a replicated log, a commit index, log sequence numbers, or leader completeness guarantees. A newly elected leader has no mechanism to determine whether it has all committed entries. Leader failover can lose in-flight writes without any visible error.
5. The file-backed KV store is not transactional.
Creating a new token requires writing four separate files: valid, policies, created_at, id. These writes are independent filesystem operations. A process crash between writes two and three leaves a half-created token. The flock locking used in the audit log (lib/audit.sh) prevents concurrent log corruption but does not provide multi-key atomic writes anywhere else in the storage layer.
6. Token revocation is not cluster-wide.
Revoking a token calls storage_kv_put "token:${id}:valid" "false" on the leader, which then replicates the single KV write to followers. However, because replication is fire-and-forget, a follower that missed the revocation write will continue accepting the revoked token on read requests (GET endpoints are served by followers). There is a brief window — potentially longer if a follower is catching up — where a revoked token remains valid.
Security Blind Spots from Deadline Pressure
No token TTL. A leaked service token grants indefinite access until an operator manually revokes it. NIST SP 800-204B and every enterprise secrets management policy require bounded token lifetimes as a default.
No rate limiting on authentication endpoints.
POST /v1/auth/loginaccepts unlimited attempts. An attacker can brute-force user passwords with no throttle, no lockout, and no alerting.AUDIT_HMAC_KEYis loaded from a.envfile that operators must manually create on each host. If this file is accidentally committed to version control, every audit log entry is compromised — an attacker can forge entries and update the chain without detection.Internal cluster traffic is authenticated by network topology alone.
/internal/*is blocked at Nginx on port 443, but any process on the Docker bridge network can send a forged heartbeat or vote request directly to port 8200 on any node. There is no application-layer authentication on cluster RPCs.No request body size limit. A caller can send a 100MB secret payload and the handler will attempt to encrypt it, consuming CPU and memory with no guard.
Argon2id work factors are hardcoded. The parameters (
m=65536, t=3, p=1) cannot be upgraded without re-hashing every stored password. There is no versioning mechanism on password hash parameters.
Section 2: New Features — Fully Designed
Feature 1: Short-Lived Tokens with Automatic Renewal
What it does and why it is needed.
Every token in V1 is immortal until explicitly revoked. In practice, service tokens are issued once and live indefinitely because operators forget to rotate them. NIST SP 800-204B mandates time-bounded credentials for secrets access. A short-lived token that auto-renews forces periodic re-authentication, significantly reducing the blast radius of a leaked credential — a stolen token becomes worthless within one TTL window.
Architectural integration.
Token creation (POST /v1/auth/token) accepts two optional parameters: ttl (default: 3600s) and max_ttl (default: 86400s). The token record gains expires_at and renewable_until timestamps. Every call to the auth middleware performs expires_at < NOW() before policy evaluation. A token renewal endpoint (POST /v1/auth/renew-self) extends expires_at by ttl up to renewable_until. A background goroutine (replacing the Bash background subshell) sweeps the tokens table every 60 seconds for expired rows, marks them revoked, and publishes a token.expired event to the internal pub/sub channel so all nodes invalidate their Redis cache entries atomically.
Data model changes.
-- Migration: add token lifecycle columns
ALTER TABLE tokens
ADD COLUMN expires_at TIMESTAMPTZ NOT NULL DEFAULT NOW() + INTERVAL '1 hour',
ADD COLUMN renewable_until TIMESTAMPTZ NOT NULL DEFAULT NOW() + INTERVAL '24 hours',
ADD COLUMN token_type TEXT NOT NULL DEFAULT 'service';
-- token_type: 'root' | 'service' | 'batch'
-- root tokens: expires_at = NULL (immortal, but audited separately)
-- batch tokens: non-renewable, short TTL (used in CI pipelines)
CREATE INDEX idx_tokens_expiry
ON tokens(expires_at)
WHERE revoked = false AND expires_at IS NOT NULL;
Trade-offs.
Every token validation now includes a timestamp comparison. This is O(1) on a cached token record but adds one Redis read per request on cache miss. The renewal flow adds a write on every TTL extension. The operational cost is that service deployments must implement renewal logic — a client that issues a token and never renews it will begin receiving 401s after one TTL window. This is intentional friction that forces engineers to think about credential lifecycle, but it requires documentation and client library support.
Feature 2: Namespace Isolation for Multi-Tenancy
What it does and why it is needed.
Every production deployment of a secrets manager serves multiple teams: platform engineers, application developers, data engineers, security teams. Without namespace isolation, a token with secret/* policy can read every team's secrets. A misconfigured CI token that is compromised exposes every secret in the vault. Namespace isolation makes the blast radius of a credential leak proportional to the namespace scope, not the entire vault.
Architectural integration.
All secret paths, policy paths, and tokens are scoped to a namespace. The API becomes /v1/ns/{namespace}/secrets/{path}. Namespaces are created by root or a namespace-admin role. A token is bound to one or more namespace IDs at creation time. The policy engine evaluates (namespace_id, path, capability) triples rather than flat (path, capability) pairs. Cross-namespace access for shared resources (e.g., a shared PKI root) is granted via explicit cross-namespace policy entries.
Data model changes.
CREATE TABLE namespaces (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
name TEXT UNIQUE NOT NULL,
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
metadata JSONB NOT NULL DEFAULT '{}'
);
-- secrets now scoped to a namespace
ALTER TABLE secrets
ADD COLUMN namespace_id UUID NOT NULL REFERENCES namespaces(id);
CREATE UNIQUE INDEX idx_secrets_ns_path
ON secrets(namespace_id, path, version);
-- tokens can span multiple namespaces
ALTER TABLE tokens
ADD COLUMN namespace_ids UUID[] NOT NULL DEFAULT '{}';
-- policies scoped to namespace
ALTER TABLE policies
ADD COLUMN namespace_id UUID NOT NULL REFERENCES namespaces(id);
Trade-offs.
Every auth check now requires a namespace lookup join. This adds one foreign key read per request. The mitigation is caching the namespace record in Redis alongside the token record — the combined cache entry is fetched in a single GET. The operational complexity cost is real: operators must manage namespace lifecycle (creation, deletion with secret migration, cross-namespace policies). A team that deploys with a single namespace gets the same behavior as V1 — the feature is additive, not forced.
Feature 3: Secret Versioning with Soft Delete, Destroy Protection, and Metadata
What it does and why it is needed.
V1's DELETE /v1/secrets/{path} permanently removes all versions of a secret with no confirmation, no recovery window, and no audit trail beyond the log entry. One misfire — a CI pipeline running against the wrong environment, a typo in a script — and a production database password is gone. SOC 2 Type II and PCI DSS both require retention of secret material for a defined period and explicit destruction workflows with dual approval for high-sensitivity paths.
Architectural integration.
DELETE in V2 performs a soft delete: it sets deleted_at = NOW() on the current version but retains the ciphertext. The secret is invisible to read operations but recoverable by an authorized token with undelete capability. Permanent destruction requires a separate POST /v1/ns/{ns}/secrets/{path}/destroy?versions=1,2,3 call, and only if the path's destroy_protection flag is false. Custom metadata (owner, team, rotation_period, last_rotated_at) is stored in the metadata JSONB column and returned with every read response.
Data model changes.
CREATE TABLE secrets (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
namespace_id UUID NOT NULL REFERENCES namespaces(id),
path TEXT NOT NULL,
version INTEGER NOT NULL DEFAULT 1,
-- Encrypted payload (AES-256-GCM; Go crypto/aes native support)
ciphertext BYTEA NOT NULL,
-- DEK wrapped by the active KEK version (envelope encryption)
dek_wrapped BYTEA NOT NULL,
kek_version INTEGER NOT NULL,
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
-- Soft delete: ciphertext retained, secret invisible to reads
deleted_at TIMESTAMPTZ,
-- Hard destroy: ciphertext zeroed, recovery impossible
destroyed_at TIMESTAMPTZ,
-- Custom operator metadata
metadata JSONB NOT NULL DEFAULT '{}',
-- Prevents accidental permanent deletion
destroy_protection BOOLEAN NOT NULL DEFAULT true,
UNIQUE(namespace_id, path, version)
);
-- Fast path for active secret reads
CREATE INDEX idx_secrets_active
ON secrets(namespace_id, path, version DESC)
WHERE deleted_at IS NULL AND destroyed_at IS NULL;
-- Retention sweeper uses this to find soft-deleted secrets past retention window
CREATE INDEX idx_secrets_deleted
ON secrets(deleted_at)
WHERE deleted_at IS NOT NULL AND destroyed_at IS NULL;
Trade-offs.
Retaining soft-deleted ciphertext consumes storage proportional to write volume and secret size. The mitigation is a configurable secret_retention_days per namespace (default: 30 days), after which the background sweeper calls destroy automatically. The index idx_secrets_deleted keeps the sweep query O(log n). The downside: teams that need "delete = immediate" for regulatory compliance must explicitly set secret_retention_days = 0 and destroy_protection = false — this restores V1 behavior but requires a conscious operator decision rather than being the default.
Section 3: Production Readiness
Security
Authentication and Authorization.
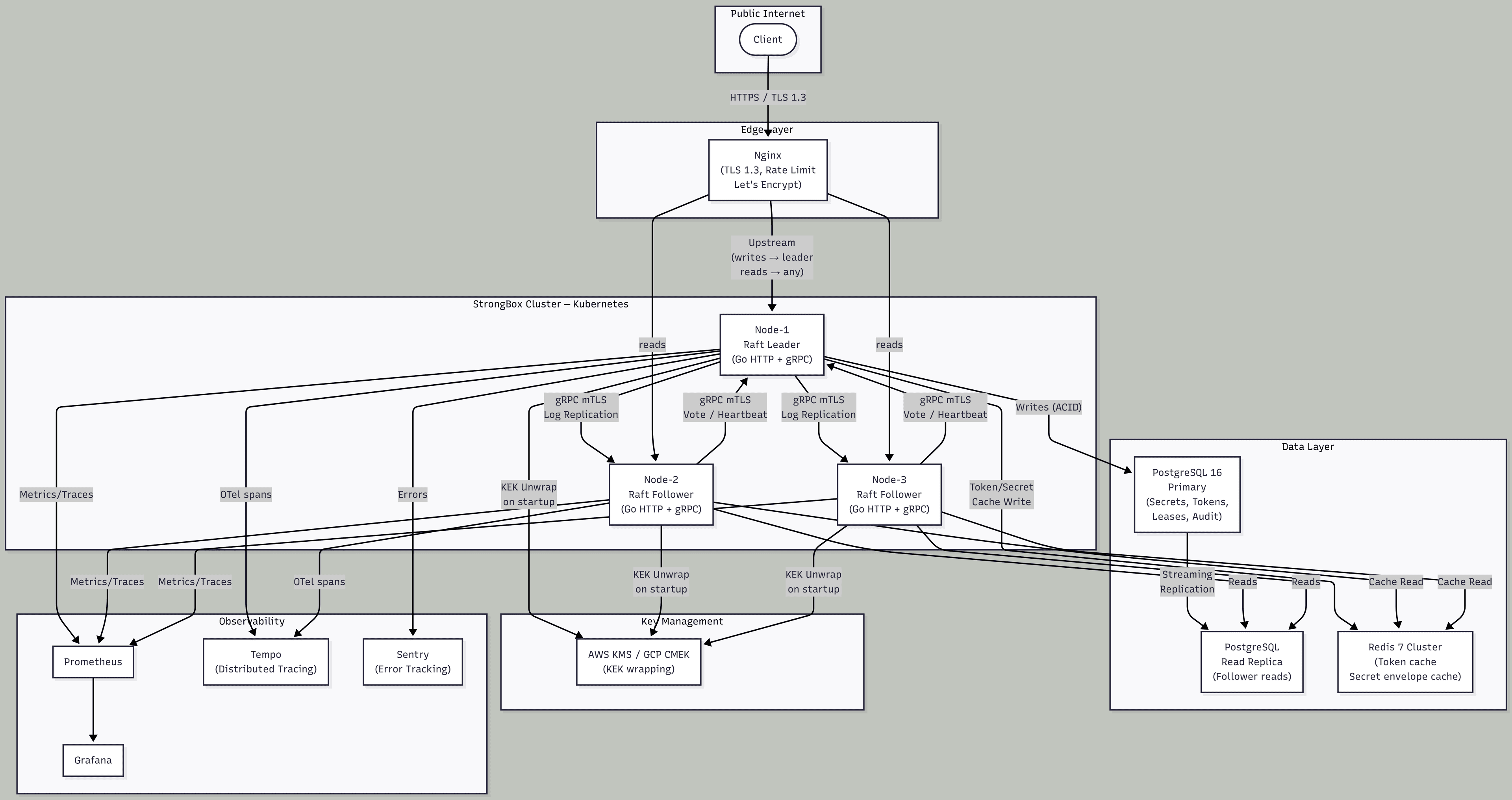
Tokens remain opaque 32-byte random hex values — not JWTs. JWTs enable offline token validation but they also enable offline token forgery if the signing key leaks; an opaque token is always validated server-side, making revocation instantaneous. Token validation hits a Redis L1 cache first (key: token:{id}, TTL: 30s). On a Redis miss the request falls through to PostgreSQL. The cache entry is invalidated synchronously on revocation and asynchronously by the TTL expiry sweeper.
Internal cluster RPCs use mutual TLS (mTLS) with node-specific certificates issued by a private cluster CA managed by cert-manager. Each node presents its certificate on every gRPC call. Peers verify the presented certificate against the CA bundle before processing any vote, heartbeat, or log replication message. This replaces the V1 approach of relying on Nginx network-layer blocking as the sole protection for cluster traffic.
High-privilege operations (namespace deletion, destroy-protection override, KEK rotation initiation) require a X-Sudo-Token header containing a short-lived (60s TTL) token issued by a separate TOTP-gated endpoint. This provides a second factor for operations that are irreversible.
Secrets management for the system itself.
AUDIT_HMAC_KEY, the PostgreSQL DSN, the Redis connection string, and the cluster CA private key are stored as Kubernetes Secrets encrypted at rest by the cloud KMS. They are injected as environment variables at pod startup via the external-secrets-operator, which pulls values from AWS Secrets Manager or GCP Secret Manager. They are never written to container images, Dockerfiles, compose files, or version-controlled .env files.
The KEK is wrapped by a cloud KMS key at rest. On startup, each node calls KMS.Decrypt to unwrap the KEK. The plaintext KEK lives only in Go process memory (a [64]byte array zeroed with runtime/debug.SetGCPercent and explicit copy(kek[:], zeros) on seal). Shamir shares remain the air-gapped recovery path for cloud KMS outages.
Input validation.
All request bodies are size-limited to 1 MB at the Nginx layer (client_max_body_size 1m). Secret paths are validated against ^[a-zA-Z0-9/_.-]{1,512}$ at the router layer — path traversal inputs like ../etc/passwd produce a 400 before touching storage. Login attempts on a single IP are throttled to 10 per minute via Nginx limit_req_zone. After 5 failed login attempts for a given username within 60 seconds, the account is locked for 5 minutes and the event is written to the audit log.
Attack surface.
All nodes run as UID 1001 (non-root) in containers with a read-only root filesystem (readOnlyRootFilesystem: true in the K8s pod spec). The gRPC internal port (9000) is bound to the pod's cluster-internal IP only — Kubernetes NetworkPolicy blocks external access. TLS 1.3 is enforced on the public listener; TLS 1.2 is disabled in Nginx. The X-Content-Type-Options: nosniff and X-Frame-Options: DENY response headers are set on all endpoints to prevent MIME sniffing and clickjacking on any browser-facing responses.
Scalability
Where writes scale vertically, reads scale horizontally.
The Raft leader is a single node — all writes must flow through it. This is not a defect; it is the price of linearizability. Vertical scaling (larger instance for the leader) increases write throughput. The leader's write path uses a bounded work queue (Go channel, depth 2,000) to absorb burst traffic; requests that overflow the queue receive a 429 Too Many Requests with a Retry-After header rather than blocking indefinitely.
Read requests (secret reads, token validations, lease queries) are served by followers from their local PostgreSQL read replica and Redis cache. Adding follower nodes scales read throughput linearly. The Nginx upstream is configured with least_conn to distribute reads across available followers; the leader is in a separate upstream group for writes only.
Cache architecture.
Two cache layers exist:
Redis (shared L2): Stores token validation results (
token:{id}→{valid, policies, expires_at}, TTL 30s) and the 10,000 most-recently-accessed secret envelopes (secret:{namespace}:{path}:latest→{ciphertext, dek_wrapped, kek_version}, TTL 5 minutes). Redis Cluster mode provides read scaling; Redis Sentinel provides HA failover. Invalidation on write: the Raft log apply callback callsredis.Del(secretCacheKey)on every committed write to that path.In-process LRU (per-node L1): A bounded 32 MB LRU cache in each Go process holds the 2,000 most frequently accessed decrypted secret values in plaintext (protected by an in-process mlock region on Linux). Eviction is LRU. This eliminates the Redis round-trip for hot secrets in sustained-traffic scenarios. The cache is invalidated on Raft log commit for the affected key.
Traffic spike handling.
A cold-start spike (new service deployment reads 500 distinct secrets simultaneously) would cause 500 simultaneous cache misses cascading to PostgreSQL. The mitigation is a per-key singleflight group: if 50 goroutines request secret/app/db_password simultaneously, exactly one goroutine executes the PostgreSQL query; the other 49 wait on the same result. This is implemented via golang.org/x/sync/singleflight and reduces the fan-out from O(concurrent requests) to O(1) per distinct key.
Observability
Structured logging.
Every log line is a JSON object with mandatory fields: ts (RFC3339Nano), level, node_id, request_id, method, path, status, duration_ms, token_id (SHA-256 hash of the token, never the token itself), namespace. The request_id is injected by Nginx as X-Request-ID and propagated through all internal gRPC calls in the context metadata. The audit log includes request_id for cross-system event correlation. Log level is dynamically adjustable via a /debug/loglevel endpoint protected by the sudo token mechanism.
Core metrics (Prometheus).
| Metric | Type | Labels | Purpose |
|---|---|---|---|
strongbox_request_duration_seconds |
Histogram | method, path, status, node_role |
Latency distribution; alert on P99 > 200ms |
strongbox_cache_hits_total |
Counter | layer (redis/l1), result (hit/miss) |
Cache effectiveness; tune TTLs |
strongbox_raft_term |
Gauge | node_id |
Term spikes indicate election instability |
strongbox_raft_commit_index |
Gauge | node_id |
Replication lag between nodes |
strongbox_lease_expiry_total |
Counter | type (secret/dynamic) |
Reaper throughput |
strongbox_token_validation_errors_total |
Counter | reason (expired/revoked/not_found) |
Anomaly detection for credential leaks |
strongbox_kek_rotation_age_seconds |
Gauge | — | Alert if KEK unrotated > 90 days |
strongbox_active_secrets_total |
Gauge | namespace |
Storage growth tracking |
Alerting thresholds.
P99 request latency > 200ms for 5 minutes → PagerDuty page (secrets access is on the critical path for every service deployment)
Raft election count > 3 in 10 minutes → Critical alert (indicates crash loop, network partition, or split-brain)
strongbox_token_validation_errors_total{reason="revoked"}rate > 100/min → Security investigation trigger (potential credential stuffing or leaked token being reused)PostgreSQL replication lag > 10 seconds on any follower → Warning (followers may serve stale auth state)
Redis unavailable for > 30 seconds → Warning (all requests fall through to PostgreSQL; write amplification spike)
Distributed error tracking.
OpenTelemetry SDK emits traces for every request, including internal Raft RPC spans. Traces are exported to Tempo. Span attributes include secret.path (truncated to path prefix, no secret value is ever included in a span), namespace_id, node.role, cache.hit. Panics and unhandled errors are captured by a Sentry middleware that attaches the current request context (minus sensitive fields) before reporting. Error deduplication is by stack trace fingerprint; the first 10 occurrences are sent, then sampled at 10%.
Section 4: Tech Stack Decisions
Every tool in V2 is here for a specific reason. "It's popular" is not a reason.
| Layer | V1 | V2 | Technical Justification |
|---|---|---|---|
| Primary language | Bash | Go 1.22 | Go's goroutine model eliminates the fork-per-request overhead that was costing 300–800ms per request in V1. The stdlib net/http server handles 50,000+ concurrent connections with goroutines scheduled on a fixed-size thread pool. Compiled binaries have no interpreter startup cost. Strong typing eliminates entire classes of V1 bugs (CRLF in integers, set -e silent failures). Memory hygiene is explicit via crypto/subtle.ConstantTimeCompare and manual zero-filling of key material. |
| Consensus | Hand-rolled election-only Raft in Bash | hashicorp/raft v1.6 |
Full Raft with log replication, log compaction (snapshots), pre-vote extension, and leader lease reads. Battle-tested in Vault, Consul, and Nomad — collectively running in tens of thousands of production clusters. Replacing the V1 elections-only approach eliminates the data-loss-on-failover gap where a new leader could win election without possessing all committed log entries. |
| Raft log store | tmpfs files (lost on restart) | bbolt (BoltDB) |
Single-file embedded B-tree with ACID writes. hashicorp/raft ships a raftboltdb.BoltStore adapter. Survives container restarts; replays the Raft log on startup. Write performance is sufficient for a secrets manager workload (single-digit MB/s of log entries). No external dependency — the store is embedded in the binary. |
| Application database | tmpfs file KV | PostgreSQL 16 | MVCC allows concurrent reads without blocking writes — critical for follower read replicas serving high-read workloads. WAL-based streaming replication propagates committed writes to read replicas with sub-second lag. JSONB natively stores secret metadata and policy rule arrays without a separate schema migration per new field. Partial indexes (WHERE deleted_at IS NULL) keep active-secret read queries O(log n) regardless of how many soft-deleted secrets accumulate. pg_partman handles time-based partitioning of the audit log for retention management. |
| Cache | None | Redis 7 (Cluster mode) | Sub-millisecond GET for token validation — PostgreSQL token lookups at P99 are 5–10ms; Redis P99 is <1ms. This matters because token validation runs on every authenticated request. Native key TTL support enforces token expiry without a separate reaper scan per request. Redis Cluster provides both read scaling (replicas) and shard-level HA. Redis Sentinel provides automatic failover with no client-side reconfiguration. |
| Internal cluster RPC | HTTP/1.1 over Docker bridge (no auth) | gRPC + Protocol Buffers over mTLS | Binary protobuf framing is 3–10× smaller than JSON for log replication payloads (the majority of cluster traffic by volume). HTTP/2 stream multiplexing allows multiple concurrent RPC calls on a single TCP connection — eliminating the connection-per-call overhead from V1's curl invocations. mTLS authenticates each node cryptographically, replacing the V1 model where any process on the Docker network could forge cluster messages. |
| Cryptography | OpenSSL CLI (subprocess), argon2 CLI (subprocess) | Go crypto/aes + golang.org/x/crypto |
AES-256-GCM (AEAD) is natively supported in Go's crypto/aes — no subprocess, no format parsing, no stdout pollution risk. GCM provides authenticated encryption in a single pass, replacing V1's CTR+HMAC two-pass approach. Argon2id via golang.org/x/crypto/argon2 — no subprocess fork overhead (300–500ms per hash in V1), parameterizable work factors with version tracking for future upgrades, and a single consistent hash format. |
| Key management | KEK in tmpfs; Shamir shares as sole unseal | AWS KMS / GCP CMEK + Shamir fallback | Cloud KMS provides HSM-backed key storage with audit trails, automatic rotation scheduling, and cross-region redundancy. The KEK's plaintext never leaves Go process memory; KMS only ever sees the wrapped form. Shamir shares remain the air-gapped recovery path for cloud outages or cross-cloud migration. This is not vendor lock-in — the KMS interface is abstracted behind a KeyManager interface, swappable with any KMIP-compliant provider. |
| Container orchestration | Docker Compose | Kubernetes (K3s for small deployments) | Pod Disruption Budgets ensure at least 2 of 3 nodes are always running during rolling upgrades. HPA scales follower pods on CPU > 70%, which handles read traffic spikes without manual intervention. Kubernetes NetworkPolicy enforces that the gRPC internal port is unreachable from outside the cluster namespace — defense in depth beyond mTLS. cert-manager issues and rotates mTLS certificates automatically. |
| Reverse proxy / TLS | Nginx | Nginx (public ingress) + Envoy sidecar (service mesh) | Nginx handles TLS 1.3 termination, rate limiting, and upstream routing for public traffic. Envoy sidecars (via Istio or Linkerd) handle mTLS between the ingress and StrongBox pods, with automatic certificate rotation — operators never manually manage certificates after initial cluster setup. The combination gives defense in depth: an attacker who bypasses Nginx still faces mTLS at the pod boundary. |
| Observability | None | Prometheus + Grafana + OpenTelemetry + Sentry | Prometheus pull-based metrics collection requires no agent on the application side — just a /metrics endpoint. Grafana provides dashboards with alerting rules co-located with the metric definitions. OpenTelemetry's vendor-neutral SDK means traces can be routed to Tempo, Jaeger, or any OTLP-compatible backend without code changes. Sentry's error grouping by stack trace fingerprint surfaces recurring failure modes without noise from one-off errors. |
| Secret injection for nodes | .env file on host |
Kubernetes Secrets + external-secrets-operator |
external-secrets-operator pulls values from AWS Secrets Manager or GCP Secret Manager into Kubernetes Secrets at pod startup. Kubernetes Secrets are encrypted at rest by the cloud KMS integration (--encryption-provider-config with the cloud KMS provider). This eliminates .env files that can be accidentally committed, exposed in build logs, or left on decommissioned hosts. |
What V2 Does Not Solve (and Why That's Acceptable)
A Principal Engineer will ask: what are you deferring? Here is the honest answer.
Horizontal write scaling. The Raft leader is still a single write bottleneck. The solution — partitioning secrets by namespace across multiple independent Raft groups — introduces cross-shard transactions for policies that span namespaces. The operational and correctness complexity does not justify the throughput gain for a secrets manager workload (writes are infrequent relative to reads; most write activity is secret rotation on a scheduled cadence, not high-frequency real-time writes). This is a V3 concern triggered by a concrete write-throughput benchmark.
Hardware security module (HSM) integration. Cloud KMS provides HSM-backed key storage but with a software API boundary. An organization handling secrets at PCI DSS Level 1 may require a FIPS 140-2 Level 3 HSM with physical tamper evidence. The KeyManager abstraction in V2 is designed to be swapped for a PKCS#11 HSM client without changes to the secrets engine. This is deferred until there is a compliance requirement.
Multi-region active-active. Raft consensus across geographically distributed nodes has latency proportional to the inter-region round-trip time (~100ms cross-continent). This makes write latency unacceptable for most applications. Cross-region replication for disaster recovery — one primary region, one passive standby — is achievable in V2.5 with PostgreSQL logical replication. Active-active multi-region writes require a different consistency model (e.g., CRDTs for non-conflicting state or application-level conflict resolution) and is out of scope.
Summary
V1 proved the concept. It demonstrated that envelope encryption, Shamir unseal, dynamic credential provisioning, Raft-based leader election, and tamper-evident auditing are all achievable from first principles, and it did so entirely in shell script. That is genuinely impressive as a learning exercise.
V2 is what you actually ship. It replaces every component that had a structural ceiling — the fork-per-request HTTP server, the fire-and-forget replication, the ephemeral state model, the subprocess-based crypto — with Go components that are designed for production loads, observable by default, and defensible to the security team. The same core architectural concepts (envelope encryption, policy-based auth, dynamic credentials, Raft consensus, HMAC audit chain) survive intact. The implementation grows up.
StrongBox V1 source code: https://github.com/Trojanhorse7/strongbox.git
Live V1 deployment: strong-box.duckdns.org