Building Insighta: Django + React + CLI Profiles Platform
Introduction
Most tutorials stop at “here’s a REST API.” They rarely walk through shipping a multi-client platform: a browser SPA that authenticates differently from a CLI, rate limiting that must work before and after JWTs, a natural-language parser that turns plain English into SQL-safe filters without calling an LLM, and the moment Django REST Framework quietly returns 404 because you reused a reserved query parameter.
Insighta is that stack — a profiles intelligence system split across three repos that share one Django backend:
- Backend — Django 5 + DRF, PostgreSQL, JWT (HS256), GitHub OAuth with PKCE, RBAC, layered rate limiting, deterministic NL search, CSV export
- Frontend — Vite + React 19 SPA: httpOnly cookies, CSRF, silent refresh
- CLI — Python Typer app: loopback OAuth, Bearer tokens, Rich terminal UI
This post is the architecture tour: what we built, why two OAuth apps exist, where limits apply, and the bugs that only show up in production.
Table of Contents
- Architecture at a glance
- Data model
- Authentication: two GitHub apps, one backend
- Middleware pipeline
- Rate limiting
- Profile aggregation
- Natural language search
- CSV export and the DRF format trap
- React SPA: cookies done right
- CLI: OAuth in the terminal
- Deployment
- Lessons learned
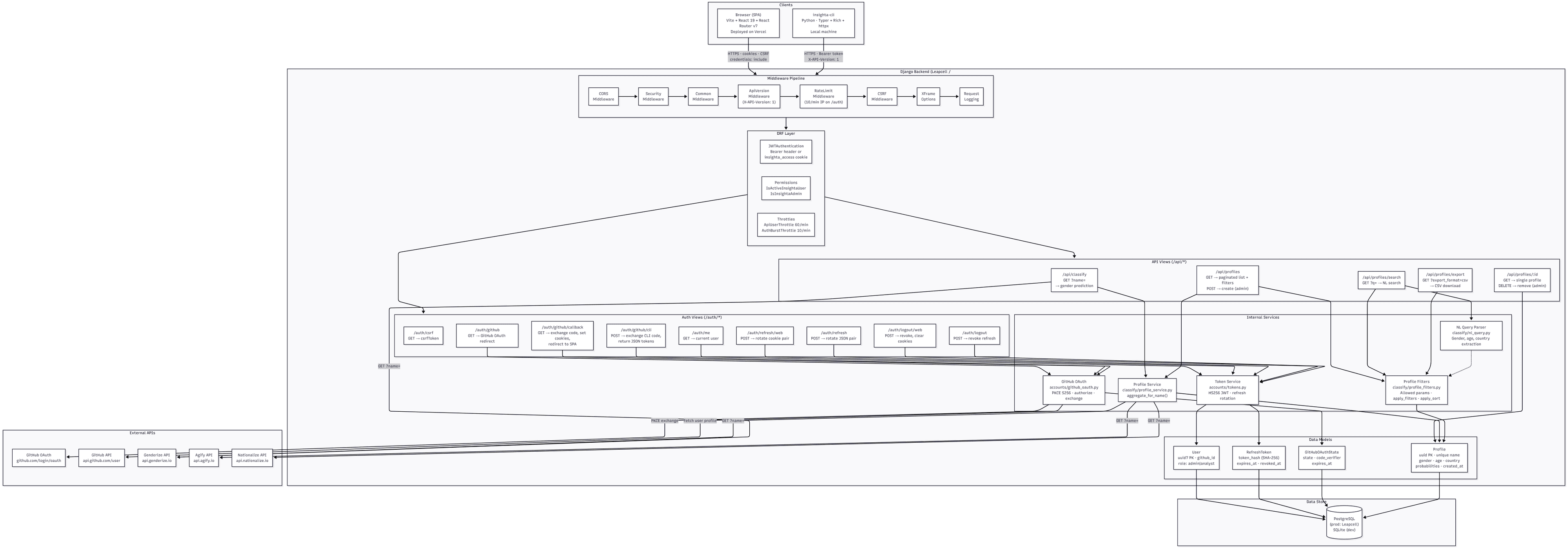
Architecture at a glance
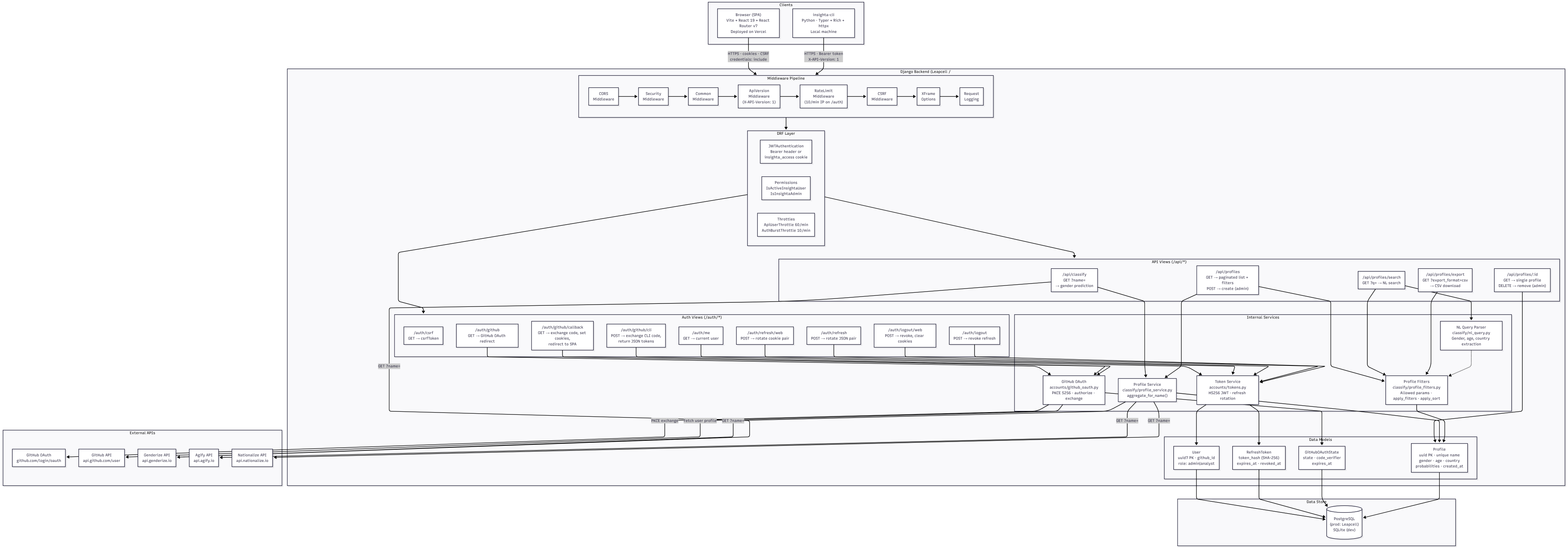
Three clients, one API:
| Piece | Stack | Auth | Deploy |
|---|---|---|---|
| Backend API | Django 5 + DRF | JWT (HS256) | Leapcell (Gunicorn) |
| Web portal | Vite + React 19 + React Router v7 | httpOnly cookies + CSRF | Vercel |
| CLI | Python 3.12+, Typer, Rich, httpx | Authorization: Bearer … |
PyPI / local |
The browser and CLI both log in with GitHub — but they use different OAuth Apps on purpose. GitHub requires callback URLs to match exactly; you cannot cleanly register both a public https://api…/callback and http://127.0.0.1:8765/callback on a single OAuth app without unsupported wildcard tricks. Two apps, two client IDs, one user table.
Data model
Four logical pieces power persistence:
User (accounts)
GitHub is the identity provider — no local passwords. A role field (admin | analyst) gates capabilities: analysts read; admins create/delete profiles.
Profile (classify)
Each row is a unique name enriched from external APIs: inferred gender and confidence, estimated age, derived age_group (child / teenager / adult / senior), and primary country with probabilities. Creating the same name twice is idempotent — you get the existing row back.
Refresh tokens & OAuth state
Refresh tokens are stored as hashes, never plaintext. GitHubOAuthState rows are short-lived: minted at the start of login, validated at callback, then discarded or expired.
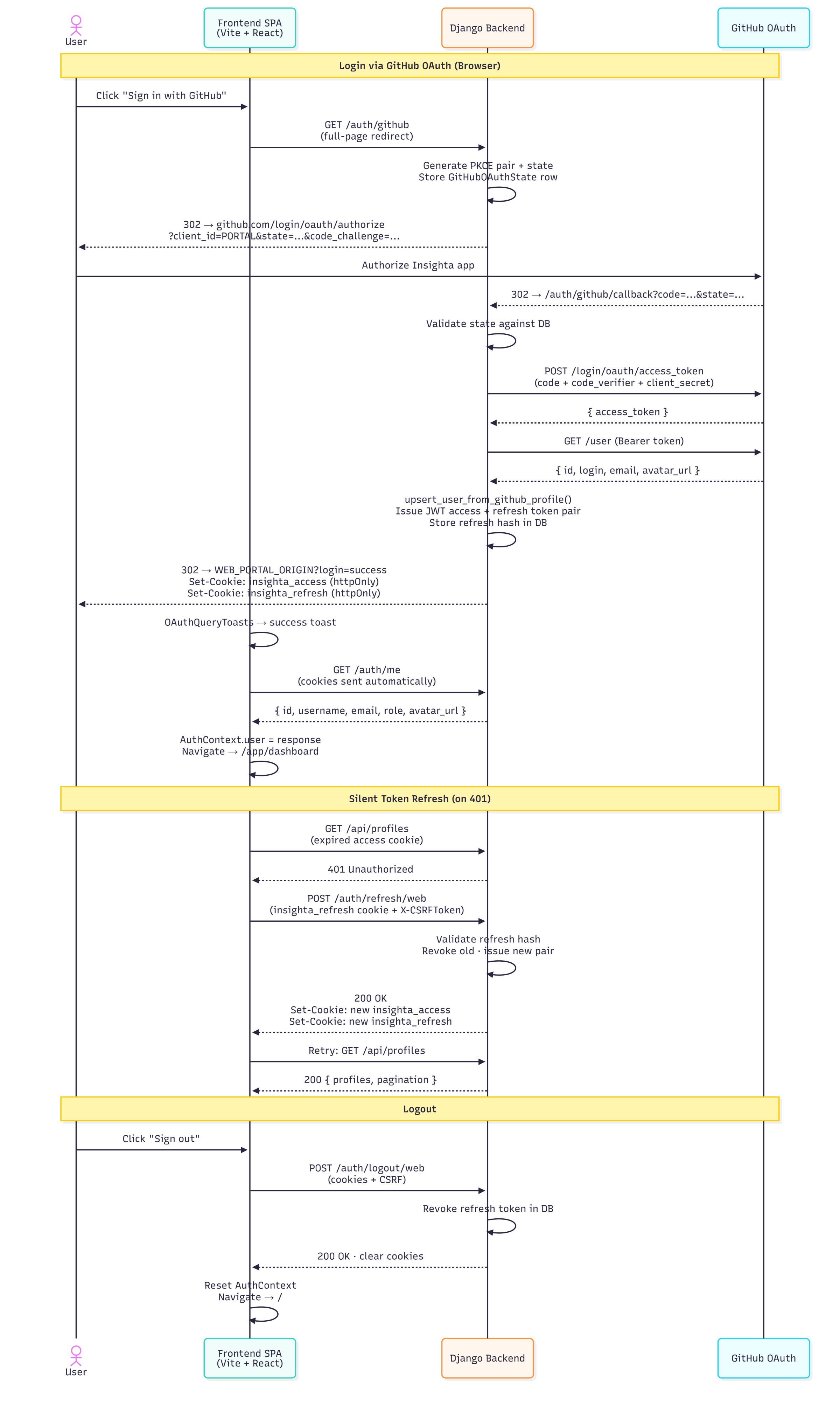
Authentication: two GitHub apps, one backend
| Browser (portal) | CLI | |
|---|---|---|
| Credentials | GITHUB_CLIENT_ID / SECRET |
GITHUB_CLI_CLIENT_ID / SECRET |
| Callback | Backend public URL | http://127.0.0.1:8765/callback |
| Token delivery | Set-Cookie (httpOnly, Secure in prod) |
JSON body → ~/.insighta/credentials.json |
| Refresh | POST /auth/refresh/web (cookies) |
POST /auth/refresh (JSON body) |
| CSRF | Required on mutating requests | Not applicable |
PKCE everywhere
Both flows implement PKCE (S256) — random verifier, SHA-256 challenge, code_challenge_method=S256 on authorize, verifier on token exchange. Even with server-side client secrets, PKCE closes the authorization-code interception window.
Portal flow (abbreviated)
User clicks “Sign in with GitHub”
→ SPA navigates to GET /auth/github (full redirect)
→ Backend stores PKCE + state, redirects to GitHub
User approves on GitHub
→ Redirect to /auth/github/callback?code=…&state=…
→ Backend validates state, exchanges code, loads GitHub profile
→ Issues JWT access + refresh, sets httpOnly cookies, redirects to SPA
→ SPA calls GET /auth/me with credentials included
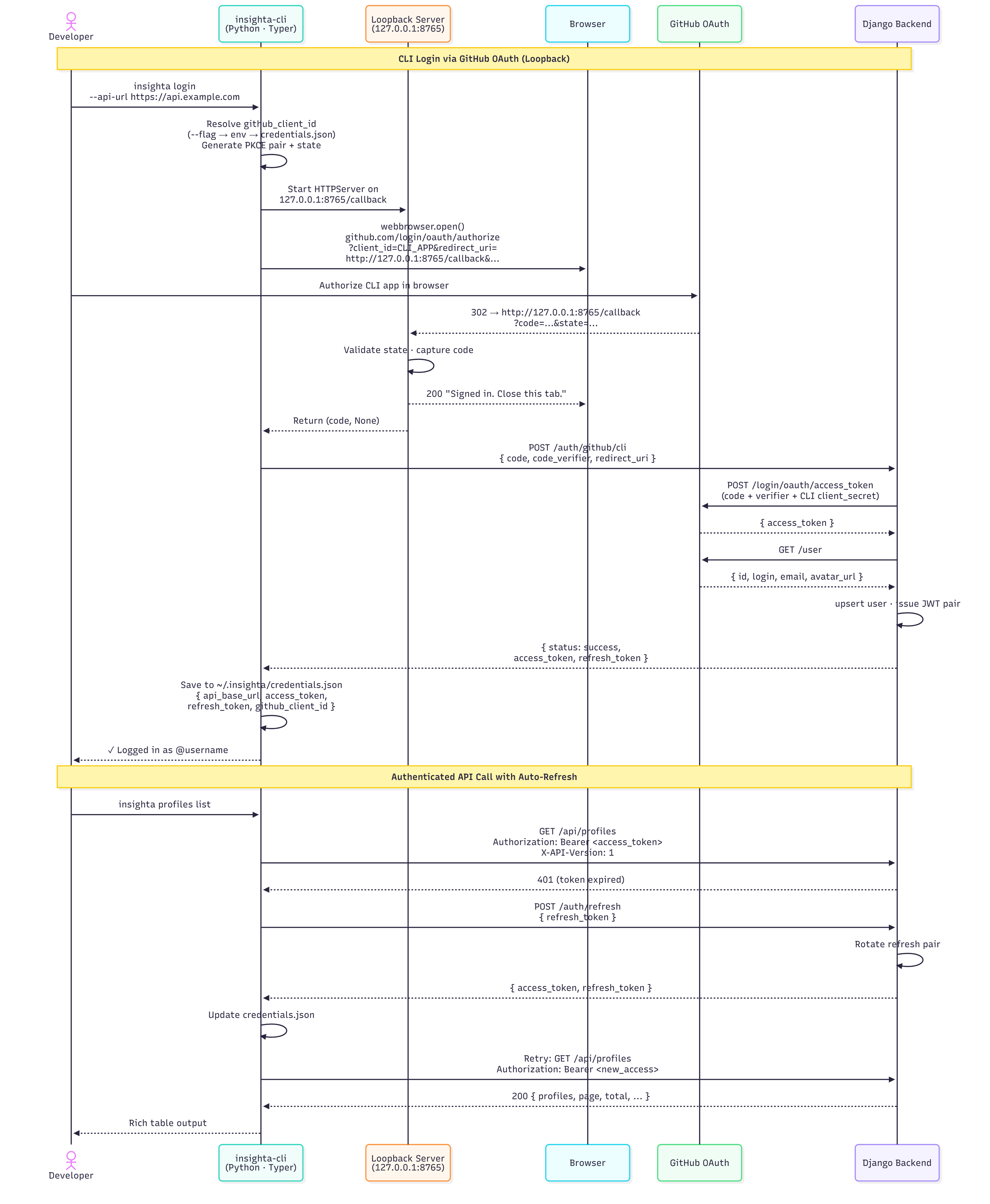
CLI flow (abbreviated)
insighta login
→ CLI binds HTTP listener on 127.0.0.1:8765
→ Opens GitHub authorize URL (PKCE + state)
GitHub redirects to loopback with ?code=…
→ CLI POST /auth/github/cli with code + code_verifier
→ Backend exchanges with GitHub using CLI app credentials
→ JSON tokens saved locally; listener shuts down
Middleware pipeline
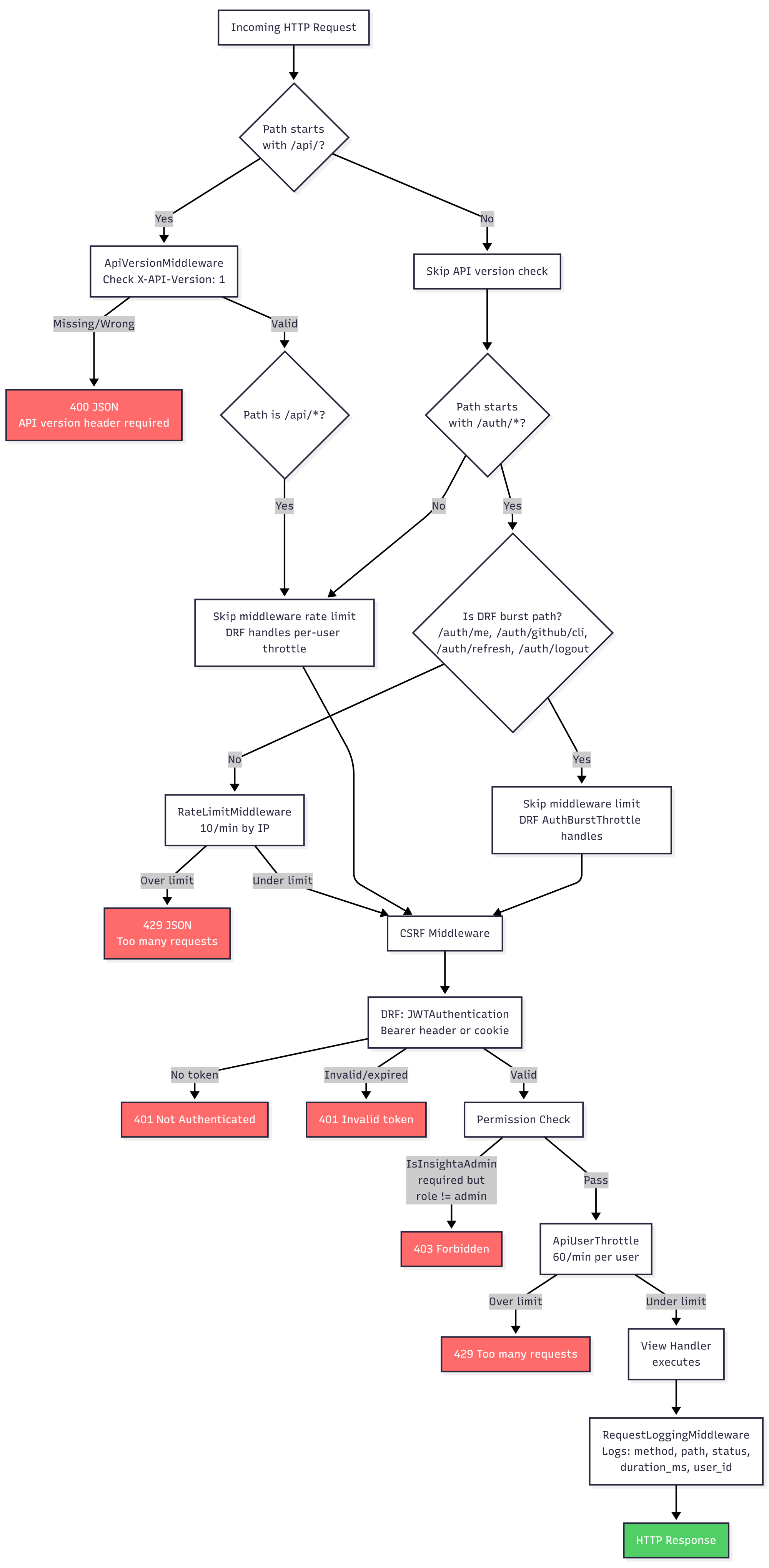
Every request walks through eight middleware layers (order matters):
1. CorsMiddleware — allow SPA origin with credentials
2. SecurityMiddleware — HSTS, SSL redirect (production)
3. CommonMiddleware — slashes, prepends, etc.
4. ApiVersionMiddleware — X-API-Version: 1 required on /api/*
5. RateLimitMiddleware — IP bucket on selected /auth/* (pre-DRF)
6. CsrfViewMiddleware — cookie-auth writes need CSRF token
7. XFrameOptionsMiddleware — clickjacking defaults
8. RequestLoggingMiddleware — method, path, status, duration, user id
API version gate
/api/* without X-API-Version: 1 returns a deliberate 400 with a clear JSON body — versioning is enforced before authentication so anonymous misconfigured clients fail fast.
{ "status": "error", "message": "API version header required" }
Rate limiting
Limits are split by layer so brute-force login attempts and authenticated API abuse are both covered:
Layer 1 — middleware (mostly pre-auth)
Roughly 10 requests/minute per IP on sensitive /auth/* routes that handle redirects and CSRF priming. Paths already throttled inside DRF views are skipped so you don’t double-penalize the same call:
# Example idea: skip what DRF handles with AuthBurstThrottle
SKIP_PATHS = [
"/auth/me",
"/auth/github/cli",
"/auth/refresh",
"/auth/logout",
]
Layer 2 — DRF throttles (post-auth)
After JWT resolution, DRF applies per-user (or per-IP for anonymous) limits on /api/*. Auth-heavy endpoints can carry their own burst throttle.
Rule of thumb: OAuth redirect surfaces → middleware IP limits; JSON token APIs → DRF. Mixing them blindly either double-counts or leaves holes.
Profile aggregation
Admin creates a profile with:
POST /api/profiles
Content-Type: application/json
{ "name": "Ada Lovelace" }
The service fans out to three public APIs:
| API | Role |
|---|---|
| Genderize | gender + probability |
| Agify | estimated age |
| Nationalize | country candidates + probabilities |
The aggregator picks the top country by probability, derives age_group from numeric age, maps ISO codes to display names, and inserts or returns the existing profile (same unique name).
Natural language search
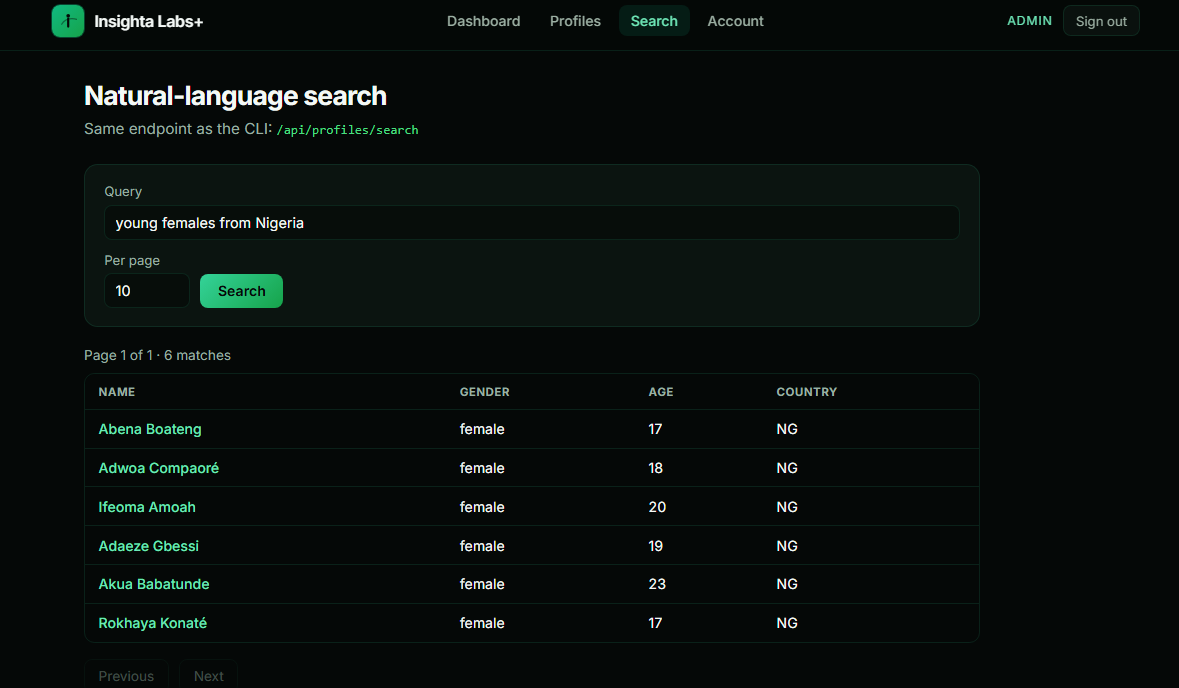
Endpoint: GET /api/profiles/search?q=…
No embeddings, no chat completions — just deterministic rules:
Input: "young males from nigeria above 20"
1. Normalize (lowercase, strip accents, collapse whitespace)
2. Longest-match country names against a curated dictionary (~65 countries)
3. Gender keywords ("male", "female", combined phrases)
4. Age-group vocabulary ("young", "teenager", "adult", …)
5. Numeric phrases ("above 20", "under 30", …) merged with age-group bounds
Output: structured filters → queryset
Example mapping
| Query fragment | Effect |
|---|---|
young |
tightens upper age bound |
males |
gender = male |
from nigeria |
country_id = NG |
above 20 |
raises minimum age |
Unparseable noise yields 422 — better than silently returning everything.
Why not an LLM here?
- Deterministic — same string, same filters; no temperature surprises
- Fast / free — microseconds, no vendor rate limits
- Testable — table-driven unit tests for phrases
When the vocabulary is small and the output shape is fixed, rules beat models.
CSV export and the DRF format trap
Everything passed locally — then production returned 404 for the export URL.
Root cause: Django REST Framework treats format as a first-class content negotiation switch. A request like:
GET /api/profiles/export?format=csv
makes DRF look for a renderer registered for csv. If none exists, you can get 404 — before your view runs. Your URLconf is fine; your tests might not hit negotiation the same way.
Fix: rename the parameter:
# Broken pattern
fmt = request.query_params.get("format", "")
# Working pattern
fmt = request.query_params.get("export_format", "")
CLI and docs must send export_format=csv instead. Lesson: grep your framework for reserved query keys before naming business parameters.
React SPA: cookies done right
Why httpOnly cookies?
JavaScript cannot read httpOnly cookies — XSS cannot exfiltrate bearer tokens from localStorage. Cookies ride automatically on same-site or correctly configured cross-site requests; refresh can rotate both tokens server-side.
Boot sequence
App mounts → GET /auth/me (cookies attached)
→ 200: hydrate user context
→ 401: POST /auth/refresh/web
→ success: retry /auth/me
→ failure: clear client state, redirect to landing
CSRF for cross-origin cookie auth
The SPA calls GET /auth/csrf early, mirrors the token into X-CSRFToken on POST/DELETE/PUT/PATCH, and relies on trusted origins + cookie flags in production.
Silent retry wrapper
A thin apiFetch helper: on 401, attempt cookie refresh once, then replay the original request. Users stay signed in until the refresh token itself expires.
CLI: OAuth in the terminal
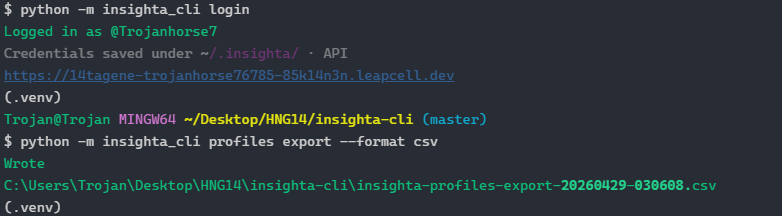
Loopback login
insighta login --api-url https://api.example.com
PKCE + random state → temporary localhost server → browser authorization → POST consolidated token exchange → credentials file.
Automatic refresh
HTTP wrapper pseudocode:
def request(self, method, path, ...):
r = self.http.request(method, url, headers=self._headers())
if r.status_code == 401 and self.refresh_token:
self._do_refresh()
r = self.http.request(method, url, headers=self._headers())
return r
Persist new tokens so the next invocation stays logged in.
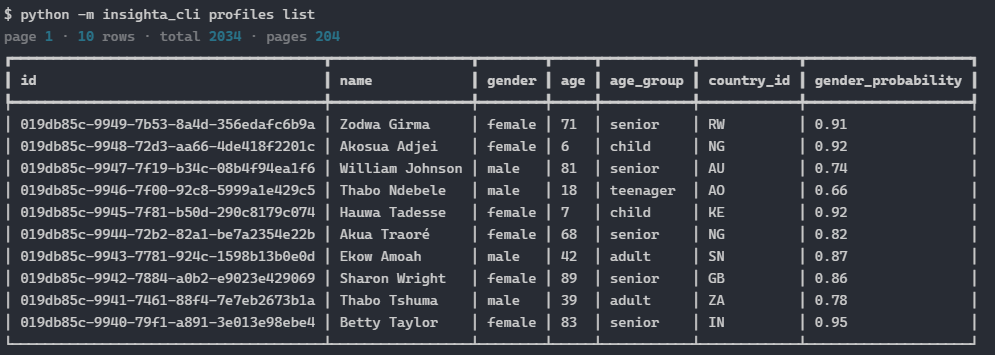
Commands (typical)
insighta login
insighta logout
insighta whoami
insighta profiles list
insighta profiles search
insighta profiles show <uuid>
insighta profiles create # admin
insighta profiles delete # admin
insighta profiles export # CSV via export_format=
insighta classify "Ada Lovelace"
Rich handles tables, spinners, and readable HTTP errors — the CLI is a product, not a thin curl script.
Deployment
| Piece | Platform | Notes |
|---|---|---|
| API | Leapcell | Gunicorn, managed PostgreSQL, TLS termination |
| SPA | Vercel | Static assets + vercel.json rewrites for client routing |
| CLI | Local / PyPI | pip install or python -m insighta_cli |
Backend env (representative)
DJANGO_SECRET_KEY
JWT_SIGNING_KEY
DATABASE_URL
GITHUB_CLIENT_ID
GITHUB_CLIENT_SECRET
GITHUB_CLI_CLIENT_ID
GITHUB_CLI_CLIENT_SECRET
BACKEND_PUBLIC_URL
WEB_PORTAL_ORIGIN
INSIGHTA_CLI_OAUTH_REDIRECT
Cross-origin cookies
SPA on Vercel talking to API elsewhere requires:
CORS_ALLOW_CREDENTIALS = True- Explicit
CORS_ALLOWED_ORIGINS(no*with credentials) CSRF_COOKIE_SAMESITE = "None"andCSRF_COOKIE_SECURE = Truein productionCSRF_TRUSTED_ORIGINSincluding the SPA origin
Local DEBUG=True can relax SameSite / Secure so http://localhost stays ergonomic.
Lessons learned
- Reserved framework words —
formatlooked innocent; DRF disagreed. When behavior is “impossible,” read how negotiation runs before your view. - Two OAuth apps — simpler and clearer than fighting callback URL constraints for browser vs CLI.
- Rate limit by responsibility — IP buckets where there is no user identity yet; per-user throttles after JWT.
- Cookies in SPAs — CSRF + CORS + cookie flags are real work, but XSS-resistant token storage is worth it.
- Small-domain NL — rules beat LLMs when inputs are bounded and outputs must be exact.
- CLI quality bar — OAuth, refresh, and UX decide whether developers keep the tool installed.
Wrapping up
Insighta grew from a Stage 1 shaped exercise into a coherent platform: three clients, two OAuth registrations, layered security, and search that never phones home to an inference API.
Repos:
- Backend: github.com/Trojanhorse7/insighta-backend
- Frontend: github.com/Trojanhorse7/insighta-frontend
- CLI: github.com/Trojanhorse7/insighta-cli
If you’re wiring cookie auth to a remote API, splitting OAuth between browser and terminal, or staring at a “404” that should be a 200 — I hope this saves you a night of debugging.
What I’d iterate on next
- Observability — structured request IDs end-to-end from SPA → API → DB slow queries.
- Webhook-style exports — async CSV generation for huge datasets instead of holding the connection open.
- Parser fuzzing — generative tests on the NL layer so odd unicode and punctuation never slip past normalization.
Questions or corrections? Comment below or open an issue on any of the repos.