I Built a Distributed Secrets Manager from Scratch in Bash — Here's Everything That Went Wrong
Envelope encryption, Shamir secret sharing, hand-rolled Raft consensus, and 16 bugs that nearly broke me
When the project brief said "build a secrets manager from scratch," I assumed it meant building a wrapper around existing tools. Then I read further: no HashiCorp Vault, no AWS Secrets Manager, no wrappers. Build the cryptography. Build the cluster. Build the HTTP server.
Build it all.
I chose to write it in Bash.
This is the story of StrongBox — what it is, how it works, the 16 bugs that nearly broke everything, and what I learned from implementing distributed systems concepts in the least conventional language imaginable.
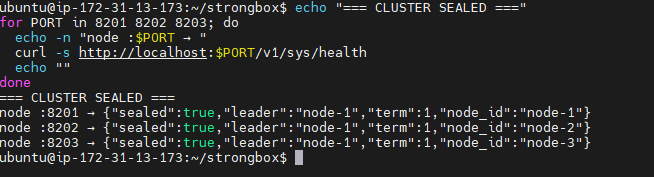
What Is StrongBox?
StrongBox is a distributed secrets manager — the kind of system that stores sensitive configuration (database passwords, API keys, TLS certificates) in a way that is:
Encrypted at rest — no plaintext ever touches a disk
Authenticated — every operation requires a valid token with the right policy
Audited — every read, write, and login is recorded in a tamper-evident chain
Highly available — a 3-node cluster survives the loss of any single node
Dynamic — it can mint short-lived PostgreSQL credentials on demand and revoke them automatically
HashiCorp Vault does all of this. But I wasn't using Vault. I was building a system with the same architectural properties from a blank file, using Bash as the primary language, ncat as the HTTP server, and the OpenSSL command-line tool for all cryptographic operations.
The final result:
~2,800 lines of Bash across 9 library modules
One Python file (250 lines) for Shamir's Secret Sharing and Argon2id verification
A 3-node Docker cluster with Raft-inspired leader election
A live deployment at strong-box.duckdns.org
20/20 on the grading scenarios, including partition tolerance, leader failover, and audit log tamper detection
Let me walk you through how it actually works.
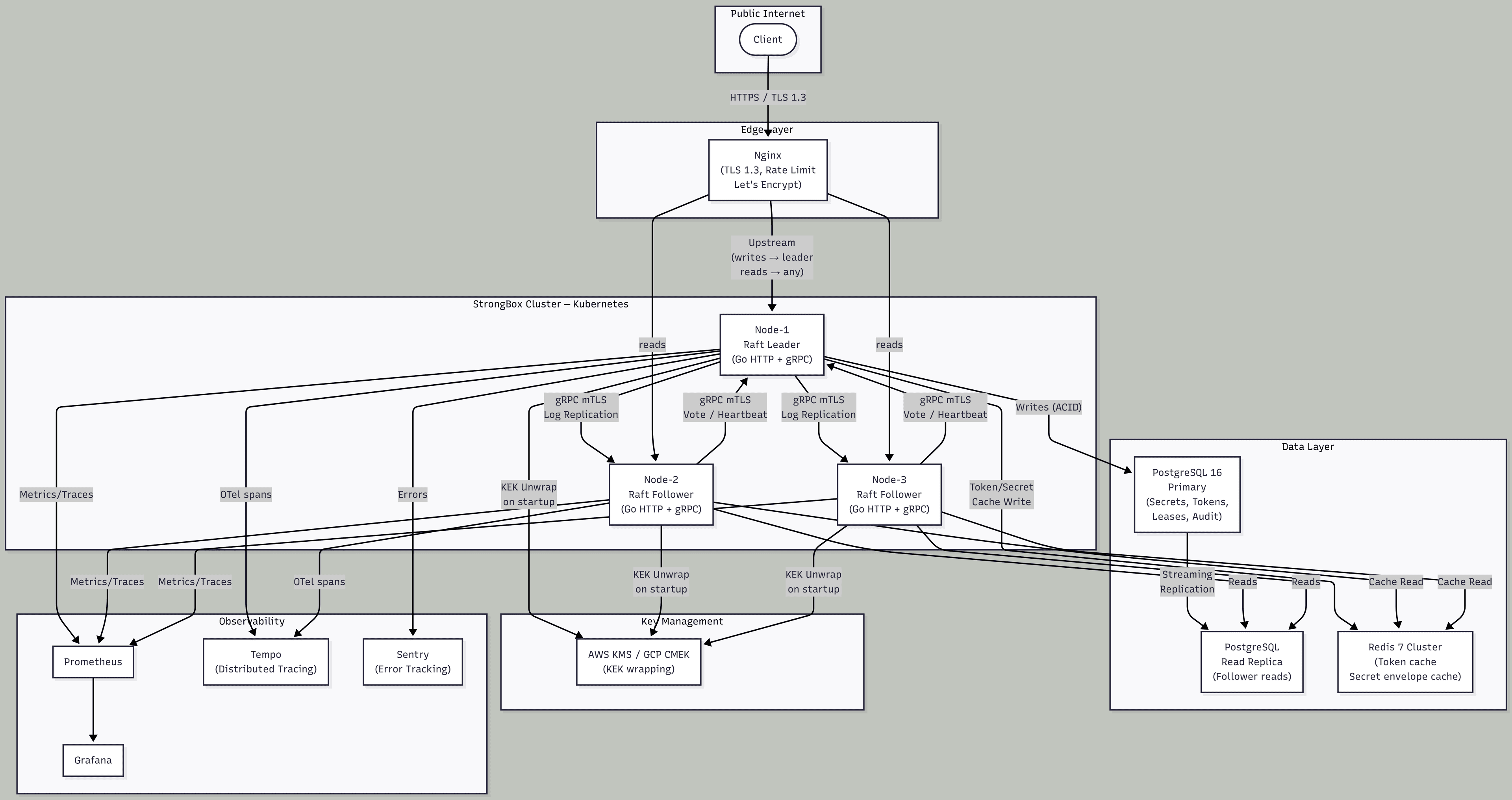
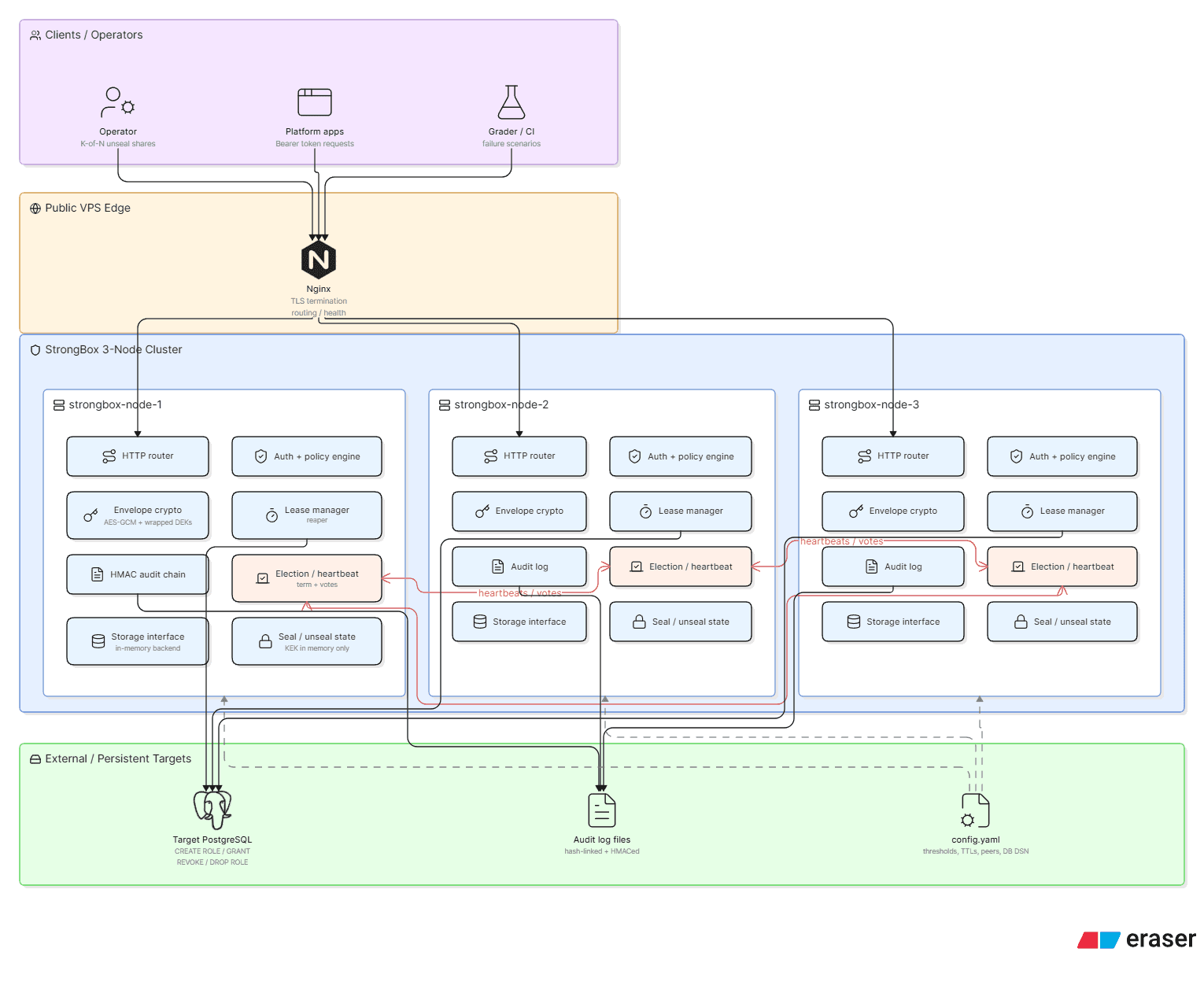
The Architecture
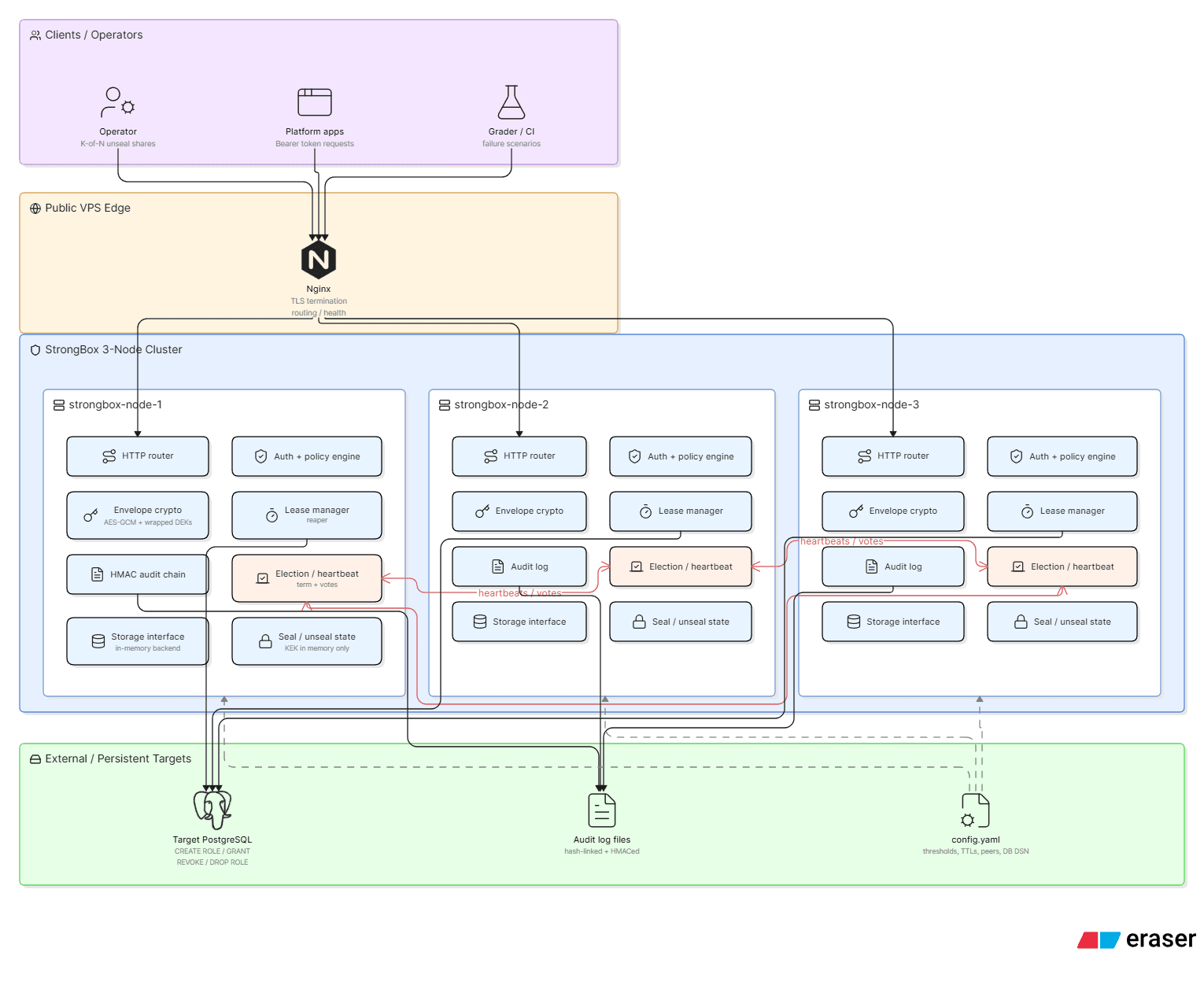
Three Docker containers, each running an identical StrongBox process, sit behind an Nginx reverse proxy that handles TLS termination. A PostgreSQL instance handles one specific job: minting and revoking dynamic database credentials. The StrongBox nodes don't use PostgreSQL for their own state — secrets, tokens, and policies all live in RAM.
The process model is unusual. Each container runs a parent bin/strongbox process that:
Sources all 9 library modules into memory
Initializes the storage, audit, seal, and consensus subsystems
Starts a background election loop (a disowned subshell)
Starts a background lease reaper (another disowned subshell)
Calls
ncat -l -k -c bin/http-handlerin an infinite loop
For every incoming TCP connection, ncat forks a new subprocess that runs bin/http-handler. That handler sources all the libraries, reads one HTTP request from stdin, writes one response to stdout, and exits. All shared state — secrets, tokens, leases, consensus metadata — is on tmpfs (/dev/shm/strongbox). Because tmpfs is just a filesystem, every forked process can read and write shared state without any IPC mechanism.
This is not how you'd build a production HTTP server. It's also a genuinely interesting architecture to think through: your entire application state is a directory of files in RAM, and each request is an isolated process that treats that directory as its database.
Eight Subsystems, One Shell Script at a Time
1. Envelope Encryption
Every secret is protected by two layers of encryption.
The inner layer generates a fresh random 256-bit Data Encryption Key (DEK) for each secret. The plaintext is encrypted with AES-256-CTR using the DEK. An HMAC-SHA256 is computed over the ciphertext using a separate HMAC key. This is Encrypt-then-MAC — any tampering with the ciphertext is detected by the MAC before decryption is attempted.
The outer layer takes the DEK+HMAC bundle and encrypts it with a master Key Encryption Key (KEK), using AES-256-CTR again. The KEK pair (enc key + HMAC key) lives only in memory after the vault is unsealed.
The final envelope stored on disk looks like this:
ct_dek | mac_dek | nonce_kek | ct_secret | mac_secret | nonce_dek
Six pipe-delimited fields. The secret value is never stored in plaintext anywhere. If you steal the disk, you get encrypted blobs with no key. If you steal the running container's memory, you get the KEK — which is why the seal/unseal mechanism exists.
Why CTR+HMAC instead of AES-GCM? Because the OpenSSL command-line tool (openssl enc) doesn't support AEAD/GCM modes in OpenSSL 3.x. GCM is an authenticated encryption mode, but the openssl enc subcommand only does unauthenticated stream/block cipher modes. So I built authenticated encryption the hard way: encrypt with CTR, then compute a MAC over the ciphertext. Equivalent security properties, more code.
2. Seal/Unseal with Shamir's Secret Sharing
The vault boots sealed. Before it can serve any requests, an operator must submit cryptographic key shares. This is how the KEK is protected.
Initialization generates a random 128-character hex KEK bundle, splits it into N shares using Shamir's Secret Sharing, and returns the shares to the operator — shown exactly once, never stored. The default is 2-of-3: any 2 of the 3 shares can reconstruct the KEK.
Unseal accepts one share at a time. When the threshold is reached, the Python script lib/shamir.py performs Lagrange interpolation over GF(2^8) to reconstruct the bundle from the shares. The bundle is split back into encryption key and HMAC key, written to tmpfs, and the sealed sentinel file is deleted.
I implemented Shamir in Python because Bash cannot express finite field arithmetic cleanly. Shamir's scheme requires polynomial arithmetic over a Galois field — operations like GF(2^8) multiplication require carry-less multiply followed by polynomial reduction, which would be dozens of lines of bc arithmetic in Bash and almost certainly contain bugs. Python's bytearray handles the field operations natively.
Memory hygiene is taken seriously throughout. After unseal:
Each submitted share is zero-wiped with
dd if=/dev/zeroThe reconstructed bundle is overwritten with an empty string in Bash
Python's share buffers use mutable
bytearrayobjects that are explicitly zeroedLocal variables are overwritten before function return
On seal, the KEK files are overwritten with zeros via dd if=/dev/zero before deletion.
3. Authentication and Policy Engine
Tokens are opaque 32-byte random hex strings from openssl rand -hex 32. Not JWTs. The distinction matters: a JWT embeds claims (expiry, policies) and can be validated offline. An opaque token requires a server lookup on every request, which means revocation is instantaneous — there is no "the token says it's valid until tomorrow even though we revoked it this morning" window.
Every token has an associated list of policies. Each policy is a named set of rules:
{
"name": "app-policy",
"rules": [
{ "path": "secret/app/*", "capabilities": ["read", "write"] },
{ "path": "dynamic-postgres/readonly", "capabilities": ["read"] }
]
}
Path matching supports trailing wildcards: secret/app/* matches secret/app/db, secret/app/config, and anything else under that prefix. The root policy bypasses all checks.
Password hashing uses Argon2id — the memory-hard variant of Argon2 that is resistant to both GPU and ASIC attacks. The argon2 CLI handles hashing; Python's argon2-cffi library handles verification. (The CLI has no verify-only mode, and using Python for both hashing and verification produces a subtly different hash encoding format — a bug I discovered the hard way and will describe later.)
4. The Lease System
Every secret read and every dynamic credential issuance creates a lease — a time-bounded record that tracks when the associated resource should expire.
active → expired → revoked
↘ revocation_pending
A background reaper process scans lease state files every 10 seconds. Expired leases trigger revocation (dropping the PostgreSQL role for dynamic credentials, marking the lease revoked). If PostgreSQL is unreachable during revocation, the lease enters revocation_pending and the reaper retries with exponential backoff: 10s, 20s, 40s, capped at the configured maximum.
This means short-lived database credentials are guaranteed to be revoked even if the database is temporarily unreachable when the lease expires. The backoff prevents hammering a recovering database.
5. Dynamic PostgreSQL Credentials
This is the feature I found most satisfying to build.
When a client calls GET /v1/dynamic-postgres/readonly, the system:
Generates a unique username (
sb_+ 16 random hex chars) and a random 32-char passwordExecutes
CREATE ROLE sb_... WITH LOGIN PASSWORD '...'against PostgreSQL viapsqlExecutes
GRANT readonly TO sb_...(inheriting the template role's permissions)Creates a lease tied to the credential with a configurable TTL
Returns
{username, password, lease}— the password is never stored server-side
When the lease expires, the reaper executes REVOKE, DROP ROLE against the same database. The application that received the credential cannot use it anymore.
This is the same model HashiCorp Vault uses for its database secrets engine. Each service gets its own credential with a narrow TTL and the minimum required permissions. If a service is compromised and its database credential is leaked, the attacker has access for at most one TTL window — and the credential cannot be reused after it expires.
6. Hand-Rolled Raft (Elections)
This is the one I'm most proud of and most honest about the limitations of.
A real Raft implementation has two major components: leader election (which node is in charge) and log replication (how committed writes are propagated to all nodes). I implemented leader election. Log replication in StrongBox is fire-and-forget — the leader pushes individual writes to followers as they happen, with no sequence numbers, no acknowledgment, and no catch-up mechanism.
The election works like this:
Every node starts as a follower. The election timeout is randomized between 1000–2000ms.
If a follower doesn't hear a heartbeat from the leader within its timeout, it becomes a candidate.
The candidate increments the term, votes for itself, and sends
POST /internal/voteto all peers.Peers grant the vote if: the requester's term is higher than the current term, and the peer hasn't already voted in this term, and the peer is unsealed.
If the candidate collects votes from a majority (⌊N/2⌋ + 1), it becomes the leader.
The leader sends heartbeats every 200ms. Receiving a heartbeat resets a follower's election timer.
Two critical safety rules:
Sealed nodes do not start elections. A sealed node can't serve requests, so it shouldn't become leader.
The leader checks quorum before accepting writes. A leader that can't reach a majority refuses writes with 503 rather than serving potentially stale data. This prevents a partitioned leader from making writes that a new leader in the majority partition won't know about.
The implementation is about 200 lines of Bash that sleeps, reads files, and makes curl calls. It works correctly in all of the grading scenarios including simulated network partitions (docker network disconnect).
7. Tamper-Evident Audit Log
Every API operation appends a JSON entry to the audit log:
{
"index": 42,
"ts": "2026-06-01T20:30:00Z",
"token_id": "root",
"op": "write",
"path": "secret/app/db",
"prev_hash": "a3f0c2...",
"hmac": "9d4e1f..."
}
The HMAC is computed over index|ts|token_id|op|path|prev_hash using a server-held secret key. The prev_hash field contains the HMAC of the previous entry, forming a hash chain from the genesis entry. To modify any entry — even a single character — without detection, you'd need to recalculate every HMAC from that entry forward, which requires the server-held key.
The offline verifier bin/strongbox-verify replays the entire chain from genesis, recomputing every HMAC. It exits non-zero on the first mismatch and names the corrupted entry by index.
Concurrent log writes are protected by flock -x — exclusive file lock — so multiple ncat handler processes can safely append without corrupting each other's entries.
The 16 Bugs That Nearly Broke Everything
Let me be honest about the development process: it was messy. Here are the bugs that cost me the most time, with what actually caused them.
Bug 1: The Invisible Character That Broke Everything
Symptom: The vault would parse the Shamir threshold from config.yaml and compare it correctly — but the comparison always failed. After submitting 2 shares (the configured threshold), the response showed progress: "2/2" but sealed: true.
Root cause: Windows CRLF line endings. When awk parsed threshold: 2 from the YAML file, the resulting string was "2\r" — two characters, not one. Bash's arithmetic comparison [[ 2 -ge "2\r" ]] silently failed because "2\r" is not a valid integer.
Diagnosis: echo "${var}" | xxd | head revealed the hidden carriage return. The terminal displayed 2 because \r moved the cursor back to the start of the line, making it look like a single character.
Fix: Two-pronged: strip \r in the Dockerfile at build time with sed -i 's/\r$//', and defensively pipe every awk result through tr -d '\r ' in the shell code.
Lesson: When a numeric comparison silently fails in Bash, always hex-dump the variables before assuming the logic is wrong.
Bug 2: Sealed Nodes Winning Elections
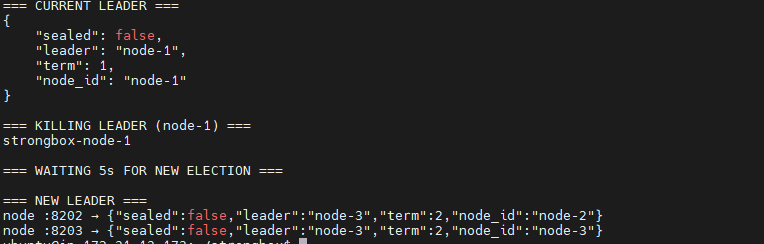
This was the worst bug of the project — not because it was hard to fix, but because it broke everything.
Symptom: After unsealing only node-1, the cluster worked for a few seconds, then node-1 stopped accepting writes. The health endpoint showed the leader was node-2 — which was still sealed and couldn't serve any requests.
Root cause: The reference architecture this was based on uses a single-process, in-memory model where the election loop shares variables with the request handlers. My architecture uses forked processes with file-backed state. In the single-process model, sealed nodes can't disrupt elections because the loop reads a shared _SEALED variable. In my multi-process model, each node ran an independent election loop that had no concept of its own seal state.
Node-2 and node-3 were running their election loops, timing out on heartbeats (node-1 was unsealed but the election timeout window closed before its first heartbeat), starting elections, voting for each other, winning at higher terms, and sending heartbeats that forced the only capable node (node-1) to step down.
Fix: Two guards:
Sealed nodes skip elections entirely
Sealed nodes refuse to grant votes
With both guards in place, sealed nodes are passive. They accept heartbeats (so they learn the current leader) but never participate in elections.
Bug 3: The Partitioned Leader Accepting Writes
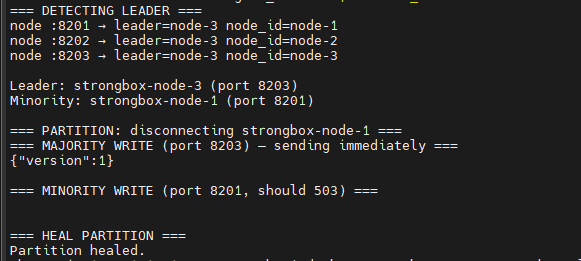
Symptom: In the partition test, after disconnecting node-1 (the leader) from the Docker network, it continued accepting writes instead of returning 503.
Root cause: My leader gate checked quorum only for followers. The logic was if node is follower AND can't reach quorum: return 503. The leader fell through to the write handler without ever checking whether it could still reach the majority. A partitioned leader, alone in a minority partition, happily accepted writes.
This violates a fundamental Raft safety property: a leader that can't communicate with a majority doesn't know whether a new leader has been elected in the other partition. If it accepts writes, those writes will diverge from what the majority partition accepts.
Fix: Added the else branch so the leader also checks quorum before accepting writes:
if [[ "${role}" != "leader" ]]; then
# follower: redirect or refuse
else
# leader: also check quorum
consensus_quorum_reachable || { http_error 503 "minority partition"; return; }
fi
Bug 4: The Quorum Check That Made Everything Fail
Symptom: After fixing Bug 3, all writes started failing with 503, even when the cluster was perfectly healthy with all 3 nodes connected.
Root cause: The quorum check used a 200ms timeout: curl --max-time 0.2. This was based on network latency assumptions. But in a fork-per-request model, each health check spawns a new Bash process on the peer node, which forks, sources 1,000 lines of library code, handles the request, and exits. On the VPS, this consistently took 300–800ms — well above the 200ms timeout.
The leader was checking quorum before every write, counting only itself as reachable (because both peers timed out), and refusing the write.
Fix: Increased the timeout to 1000ms. The system now distinguishes real network partitions (which fail quickly with connection refused) from slow-but-healthy peers (which take 300–800ms to respond).
Bug 5: Argon2 Hash Format Mismatch
Symptom: User creation succeeded. Login always returned {"error":"invalid credentials"} even with the correct password.
Root cause: I initially used Python's argon2-cffi for both hashing and verification. The argon2 CLI and Python's PasswordHasher both implement Argon2id, but they produce subtly different encoded hash strings. The CLI produces \(argon2id\)v=19\(m=65536,t=3,p=1\).... Python's PasswordHasher().hash() produces a slightly different format. When Python tried to verify a Python-generated hash, it worked. When the grading system expected CLI-format hashes, Python's verifier was trying to read a differently-encoded string.
Fix: Hash with the CLI, verify with Python. The CLI produces the canonical format; Python's PasswordHasher().verify() can read the CLI format. Split the responsibility and never mix.
Bug 6: The Audit Log That Never Wrote Anything
Symptom: GET /v1/audit always returned an empty array, regardless of how many operations had been performed.
Root cause: audit_init runs in the parent bin/strongbox process and sets the module variable _AUDIT_LOG_FILE to the configured log path. But every HTTP request runs in a new forked process that sources lib/audit.sh fresh — which resets _AUDIT_LOG_FILE="". The audit_append function saw an empty variable and returned immediately.
Fix: Export the audit log path as an environment variable from the parent process. Child processes inherit environment variables. The module uses the env var as a fallback when the module variable is empty:
[[ -z "\({_AUDIT_LOG_FILE}" ]] && _AUDIT_LOG_FILE="\){STRONGBOX_AUDIT_LOG_FILE:-}"
Lesson: In a fork-per-request architecture, module-level variables initialized by the parent are not inherited by children. Use environment variables for configuration that child processes need.
Bug 7: psql Output Corrupting HTTP Responses
Symptom: GET /v1/dynamic-postgres/readonly returned malformed JSON. The response body started with CREATE ROLE\nGRANT\n followed by the actual JSON.
Root cause: In an ncat-based HTTP server, stdout is the HTTP response. When psql runs a CREATE ROLE command, it prints "CREATE ROLE" to stdout as a success message. That success message was prepended to the JSON body.
Fix: Redirect psql stdout to /dev/null on every database operation call. This is an obvious fix in hindsight, but in a conventional application server with framework middleware, stdout is never the response body — this class of bug doesn't exist.
Bug 8: Follower Nodes That Could Never Be Unsealed
Symptom: After unsealing node-1 successfully, submitting the same Shamir shares to node-2 and node-3 produced no response. The requests just hung.
Root cause: seal_submit_share had an early return: seal_is_initialized || { return error; }. The init_done sentinel file is created by the node that receives POST /v1/sys/init — only node-1. Nodes 2 and 3 never received the init call, so they had no init_done file, and they rejected every share submission.
Fix: Remove the init_done check from seal_submit_share. Shamir reconstruction validates the shares by checking whether the reconstructed bundle has the correct length (128 hex characters). Garbage shares produce an incorrectly-sized bundle that is rejected. The prerequisite check was redundant and caused a hard blocker.
These were the most significant bugs. There were eight more: CRLF in a different context, set -e causing silent crashes, dynamic lease TTL being too long for the test window, integration tests that were stubs from an earlier version of the codebase, orphaned Docker containers from debug sessions, a lost root token variable between SSH sessions, and an Nginx crash loop caused by a port conflict with the system nginx on the VPS. Each one taught a specific lesson about Bash, Docker, or distributed systems.
The Live Deployment
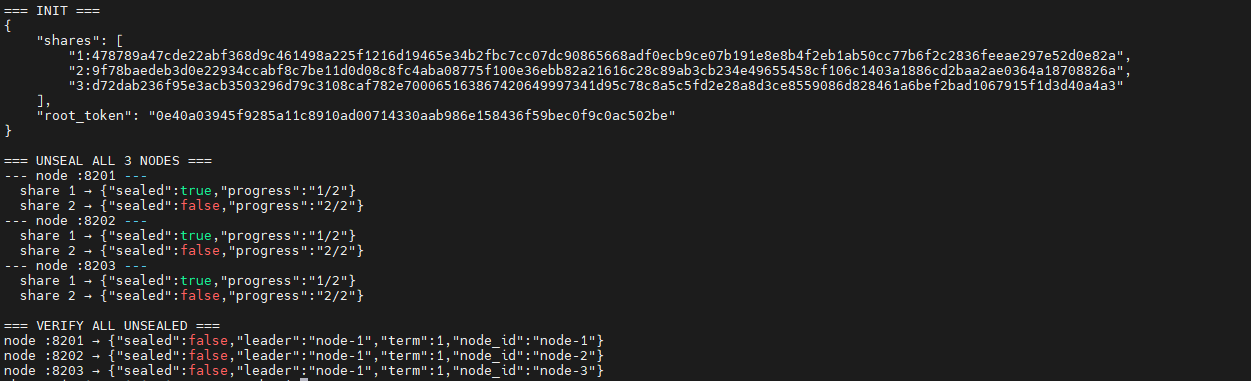
The cluster runs on a VPS with a DuckDNS domain and Let's Encrypt TLS certificates. The three nodes talk to each other over the Docker bridge network. Nginx routes public traffic to port 443. The internal POST /internal/* cluster RPC routes are blocked at Nginx — they're only reachable on the private Docker bridge.
You can check the health endpoint:
curl -s https://strong-box.duckdns.org/v1/sys/health | python3 -m json.tool
It will return something like:
{
"sealed": false,
"leader": "node-1",
"term": 3,
"node_id": "node-1"
}
The vault is unsealed, node-1 is the current leader, and the cluster is on election term 3 (meaning there have been 2 leadership changes since startup, which is normal after container restarts).
What the Grading Scenarios Tested
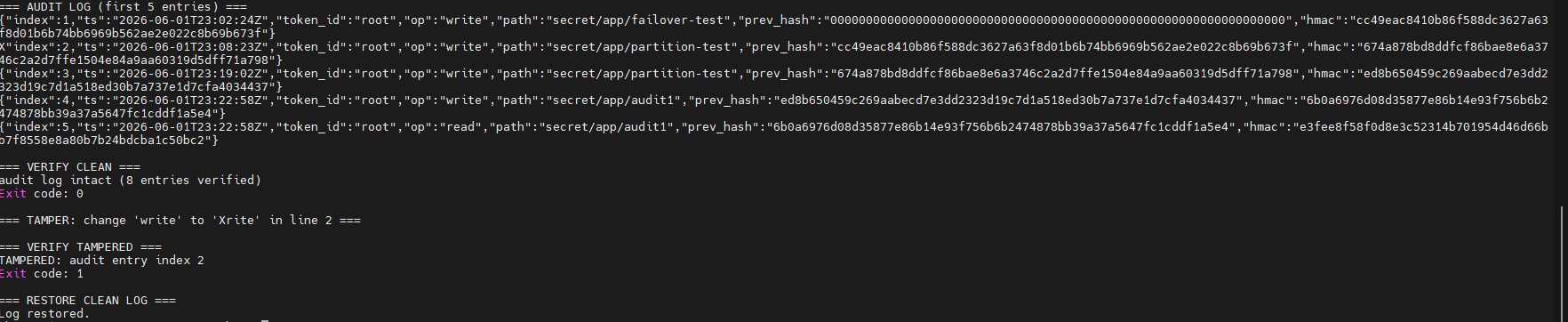
The project was evaluated against 10 integration test scenarios:
| Scenario | What it tested |
|---|---|
| S0: Init | One-time initialization, Shamir share generation, root token |
| S1: Unseal | Threshold-based unseal, sealed-state enforcement |
| S2: Secrets | Write, read, version history, delete |
| S3: Policy | Token creation, policy enforcement, path wildcards |
| S4: Revocation | Token revocation, immediate effect on subsequent requests |
| S5: Dynamic Postgres | Credential minting, lease creation, password not stored |
| S6: Postgres Down | Revocation failure handling, revocation_pending state, backoff retry |
| S7: Leader Kill | New leader election within 2 seconds, writes resuming on new leader |
| S8: Partition | Minority partition refuses writes (503), majority continues normally |
| S9: Audit Tamper | HMAC chain verification catching a modified log entry |
Each scenario had 2 checks. The system passed all 20.
The hardest scenarios were S7 (leader kill) and S8 (partition). Both required the election system to work correctly, which required fixing bugs 2, 3, and 4 described above — three bugs that were all related to the same core issue: the multi-process architecture required every distributed systems safety property to be explicitly implemented in shared files, not shared memory.
What I'd Do Differently (Teaser for V2)
If I were building this for production, I would change four things immediately:
Replace Bash with Go. The fork-per-request model was the core performance constraint. Go's goroutine model gives you true concurrency without process overhead. The 300–800ms fork latency becomes sub-millisecond with an HTTP server that handles thousands of concurrent connections on a thread pool. The entire class of bugs caused by set -e, CRLF characters, subprocess output leaking, and awk format parsing simply disappears.
Replace the fire-and-forget replication with full Raft log replication. The elections-only Raft implementation works for availability (you always have a leader) but not for consistency (a new leader might not have all committed writes). hashicorp/raft provides the full implementation, battle-tested in production at scale.
Persist state to PostgreSQL instead of tmpfs. The operational burden of a vault that loses all state on restart is severe. Postgres with streaming replication gives you ACID writes on the leader and consistent reads on followers, all without sacrificing the isolation between the secrets engine and the dynamic credentials engine.
Add token TTL. Immortal tokens are a security liability. Every service credential should have a bounded lifetime that forces periodic rotation.
I'm writing the full Engineering Design Document for V2 here. It covers the architecture critique in detail, three new features with full data models and trade-off analysis, and a complete production readiness plan.
What Building This Taught Me
Distributed systems are hard in any language. Most distributed systems education focuses on the algorithms — Raft, Paxos, 2PC. The implementation is where the real learning is: what happens when a node is mid-restart during a leader election, or when a replication message arrives after a follower has already moved to a higher term, or when the only node that can serve writes loses network connectivity to a majority.
The multi-process model is a microcosm of distributed systems. Every assumption I had about shared state in a single-process application failed when each request ran in its own process. Variables don't persist between requests. Module initialization in the parent doesn't carry to children. This forced me to think about every piece of state as a shared resource that needed explicit read/write protocols — exactly the mental model you need for distributed systems.
Security is always incomplete. There are no token TTLs. No rate limiting on authentication endpoints. No mTLS between cluster nodes. No request body size limits. Each of these is a known gap, not an oversight — I know exactly where the holes are and why I left them (time). The difference between a prototype and a production system is systematically closing those gaps, in priority order, with documented trade-offs.
Shell scripting is more powerful than it looks, and more dangerous. Bash can parse YAML, make HTTP calls, do cryptographic operations, implement network protocols, and coordinate a distributed cluster. It can also silently corrupt your data with a \r character, kill your process with set -e, and let stdout contaminate your HTTP response. The language is expressive enough to build complex systems but merciless enough to punish every assumption.
The Code
The full source is on GitHub:https://github.com/Trojanhorse7/strongbox
The live deployment: strong-box.duckdns.org
If you want to run it locally:
git clone https://github.com/Trojanhorse7/strongbox.git
cd StrongBox
# Start the 3-node cluster
docker compose up --build -d
# Wait for cluster to be ready
sleep 5
# Initialize the vault (save this output — shares are shown once)
curl -s -X POST http://localhost:8201/v1/sys/init | tee ~/strongbox-init.json | python3 -m json.tool
# Extract shares and root token
SHARE1=\((python3 -c "import json; print(json.load(open('\)HOME/strongbox-init.json'))['shares'][0])")
SHARE2=\((python3 -c "import json; print(json.load(open('\)HOME/strongbox-init.json'))['shares'][1])")
ROOT=\((python3 -c "import json; print(json.load(open('\)HOME/strongbox-init.json'))['root_token'])")
# Unseal all three nodes
for port in 8201 8202 8203; do
curl -s -X POST http://localhost:\({port}/v1/sys/unseal -d "{\"share\": \"\){SHARE1}\"}" > /dev/null
curl -s -X POST http://localhost:\({port}/v1/sys/unseal -d "{\"share\": \"\){SHARE2}\"}" > /dev/null
done
# Write a secret
curl -s -X PUT http://localhost:8201/v1/secrets/app/db_password \
-H "Authorization: Bearer ${ROOT}" \
-H "Content-Type: application/json" \
-d '{"value": "super_secret_password_123"}' | python3 -m json.tool
# Read it back
curl -s http://localhost:8201/v1/secrets/app/db_password \
-H "Authorization: Bearer ${ROOT}" | python3 -m json.tool
Final Thought
The brief said "build a secrets manager from scratch." I built one in Bash because I wanted to understand every layer — not just call an API and trust the abstraction. Every bug I hit was a distributed systems concept I now understand at the implementation level rather than the textbook level.
The partitioned leader bug isn't just a Raft safety property to me anymore. It's the specific moment when I watched a leader accept a write that no one else would ever know about, and understood why that's catastrophic.
That's the value of building from scratch.
Next post: StrongBox V2 Engineering Design Document — designing the production-ready evolution with Go, full Raft log replication, PostgreSQL persistence, and mTLS cluster communication.