I Built a Self-Service Sandbox Platform with Docker, Nginx, and Bash — Here's How It All Works
A miniature internal Heroku: isolated Docker environments, dynamic nginx routing, TTL-based auto-cleanup, outage simulation, health monitoring, and a REST control API — all on one Linux VM
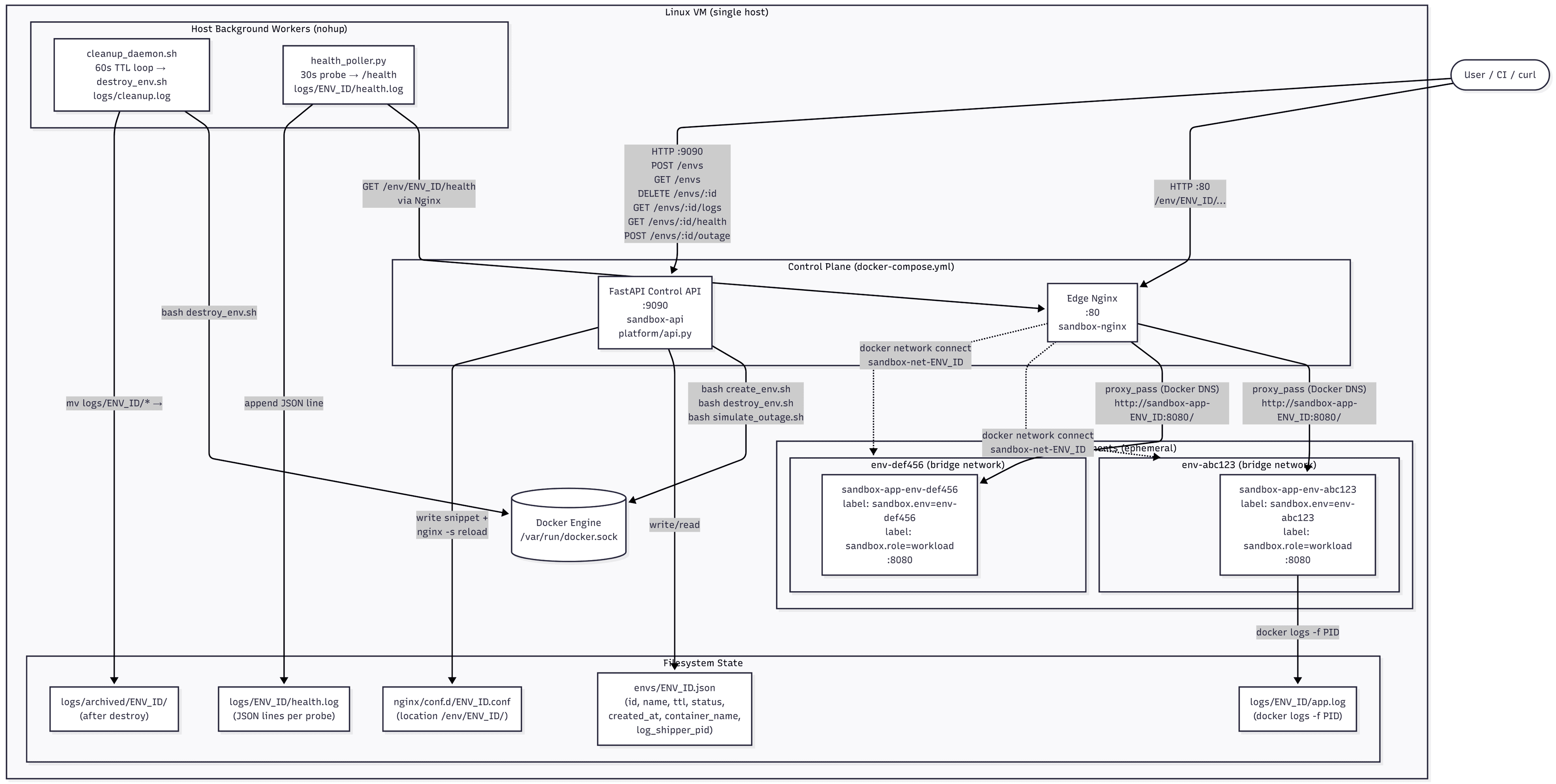
I wanted to build something that captures the real operational concerns of a platform team in a small, understandable package — not a toy "Hello World in Docker," but a system where you can actually see environments spin up, routes register, health monitors fire, and chaos strike. What came out is a self-service sandbox platform: a miniature internal Heroku with a chaos engineering toggle, running entirely on one Linux VM.
Full source: Trojanhorse7/devops-sandbox
What the platform does
The platform lets you spin up isolated, temporary environments on demand. Each environment is:
- A Docker container running an app, on its own Docker network
- Reachable at a unique URL:
http://<host>/env/<ENV_ID>/ - Tracked with a JSON state file that records name, creation time, TTL, and status
- Self-destructing after its TTL expires
- Observable through a live health monitor and a REST API
The whole control plane boots with one command:
make up
From there, creating an environment, simulating an outage, tailing logs, and triggering auto-cleanup all flow from either the Makefile or the HTTP API.
Repo layout
devops-sandbox/
├── platform/
│ ├── create_env.sh # spin up a new environment
│ ├── destroy_env.sh # tear it down
│ ├── cleanup_daemon.sh # TTL-based auto-expiry loop
│ ├── simulate_outage.sh # chaos modes: crash / pause / network / recover / stress
│ ├── api.py # FastAPI control plane
│ └── common.sh # shared config + atomic-write helpers
├── nginx/
│ ├── nginx.conf # static master config
│ └── conf.d/
│ └── env-bootstrap.conf # always-present stub
├── monitor/
│ └── health_poller.py # polls /health every 30s
├── envs/ # runtime state files (.gitignored)
├── logs/ # per-env app + health logs (.gitignored)
├── Makefile
└── docker-compose.yml
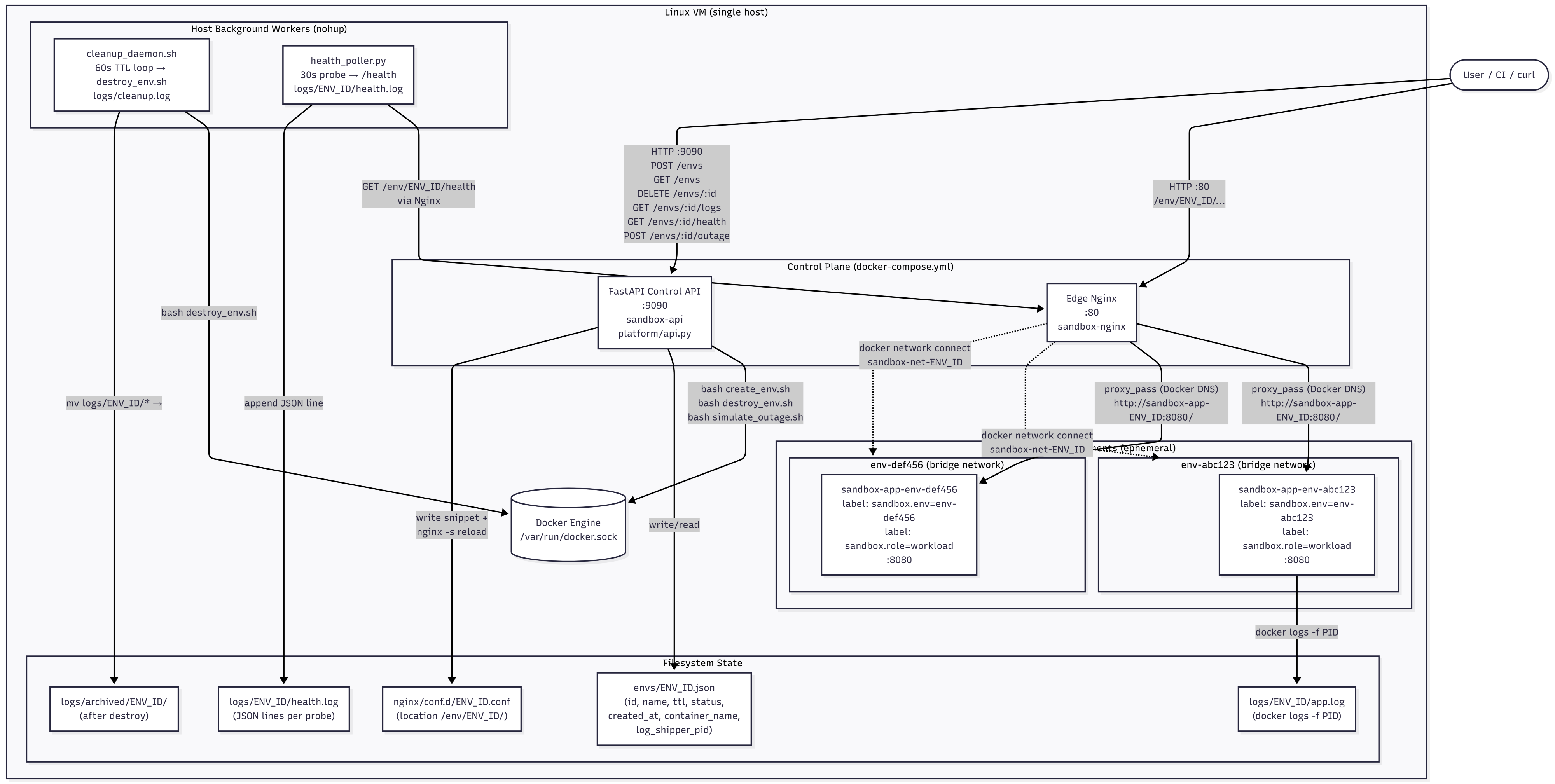
The core architecture decision: one nginx, many routes
The platform's front door is a single nginx container. It has a static master config that never changes at runtime. What changes are the files in conf.d/.
server {
listen 80 default_server;
server_name _;
location / {
default_type text/plain;
return 200 'sandbox edge — routes live under /env/<ENV_ID>/\n';
}
# Dynamically populated — one file per active environment
include /etc/nginx/conf.d/env-*.conf;
}
The include directive with a glob expression tells nginx to read every matching file and paste its contents inline before the config is parsed. When a new environment is created, a snippet is written to disk. When it's destroyed, the snippet is deleted. After each change, nginx -s reload sends SIGHUP to the master process — it forks new workers with the fresh config, drains the old ones gracefully, and replaces them. Existing connections are never dropped.
The glob edge case. If env-*.conf matches zero files, nginx refuses to start:
nginx: [emerg] open() "/etc/nginx/conf.d/env-*.conf" failed (2: No such file or directory)
The fix is a committed stub called env-bootstrap.conf that always matches the glob and doubles as an internal health endpoint:
# Always present so `include env-*.conf` matches ≥1 file.
location = /__sandbox_nginx_ok {
access_log off;
return 204;
}
The Docker Compose volume binding is what makes host-side writes immediately visible inside the container:
volumes:
- ./nginx/nginx.conf:/etc/nginx/nginx.conf:ro # master config — immutable
- ./nginx/conf.d:/etc/nginx/conf.d # snippets — read-write bind mount
nginx.conf is mounted :ro so nothing inside the container can accidentally corrupt it. conf.d/ is a plain bind mount: writes from the API container to ./nginx/conf.d/ on the host filesystem appear instantly at /etc/nginx/conf.d/ inside the nginx container. No rebuild, no copy, no restart — just a reload.
Environment lifecycle
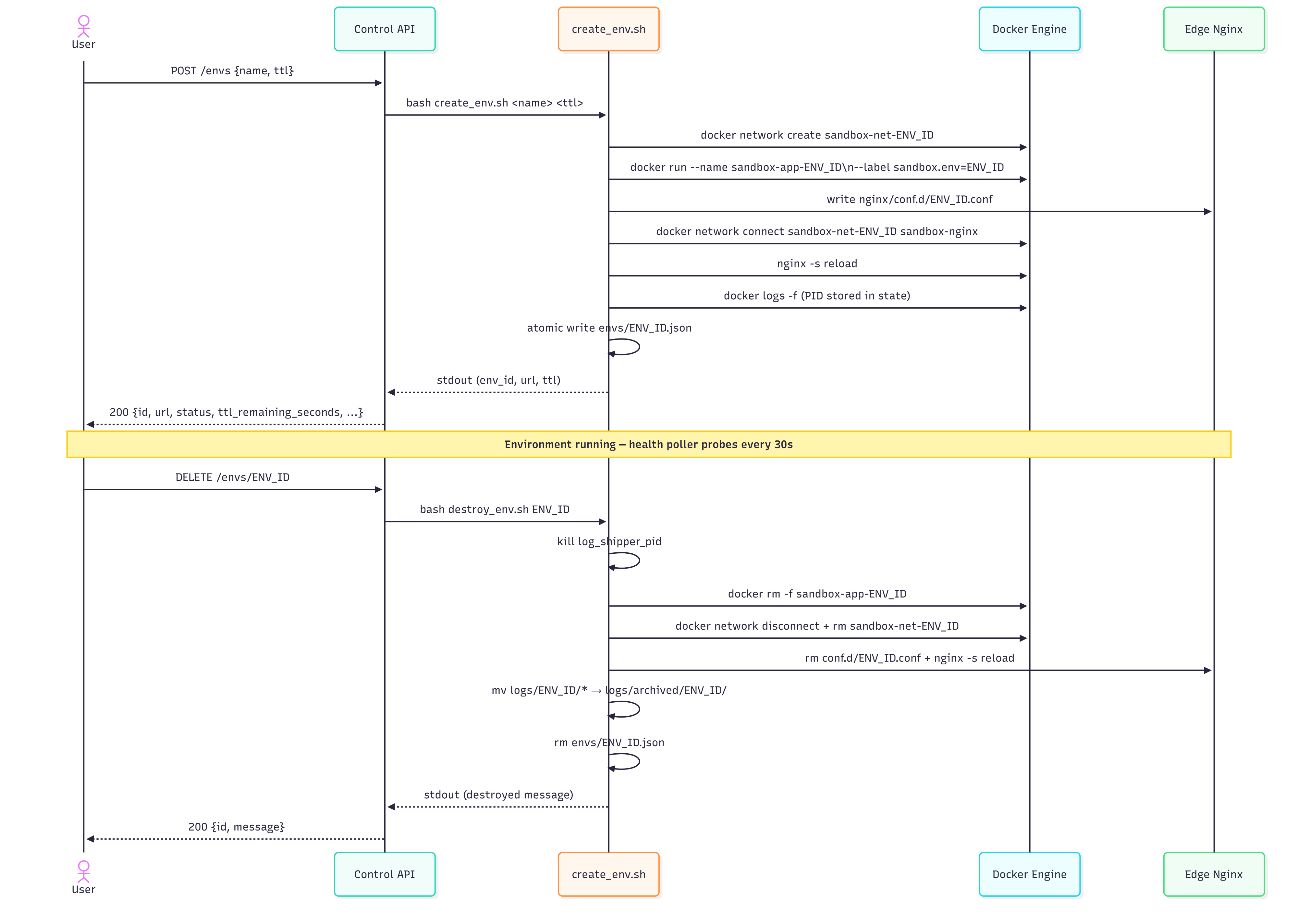
Creating an environment
create_env.sh takes a name and an optional TTL (default 30 minutes). Here's what it does in sequence:
1. Generate a unique ID and set up infrastructure
ENV_ID="env-$(openssl rand -hex 8)"
NETWORK_NAME="sandbox-net-${ENV_ID}"
CONTAINER_NAME="sandbox-app-${ENV_ID}"
docker network create "${NETWORK_NAME}"
docker run -d \
--name "${CONTAINER_NAME}" \
--network "${NETWORK_NAME}" \
--label "sandbox.env=${ENV_ID}" \
--label "sandbox.role=workload" \
-e "SANDBOX_ENV_ID=${ENV_ID}" \
-e "PORT=8080" \
"${DEMO_IMAGE}"
Every container is labeled sandbox.env=<ID> and sandbox.role=workload. These labels are how destroy_env.sh finds containers to remove and how simulate_outage.sh refuses to run against control-plane containers.
2. Write the nginx snippet — atomically
cat > "${NGINX_SNIPPET}.tmp" <<EOF
location /env/${ENV_ID}/ {
proxy_pass http://${CONTAINER_NAME}:8080/;
proxy_http_version 1.1;
proxy_set_header Host \$host;
proxy_set_header X-Real-IP \$remote_addr;
proxy_set_header X-Forwarded-For \$proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto \$scheme;
}
EOF
mv -f "\({NGINX_SNIPPET}.tmp" "\){NGINX_SNIPPET}"
Writing to a .tmp file first, then renaming with mv, is critical. mv within the same filesystem is an atomic syscall (rename(2)). If nginx reloads mid-write and reads a partial file, the config parse fails. The .tmp → mv pattern ensures nginx either sees the complete file or nothing.
3. Connect nginx to the environment's network, then reload
docker network connect "\({NETWORK_NAME}" "\){NGINX_CONTAINER_NAME}"
docker exec "${NGINX_CONTAINER_NAME}" nginx -s reload
Nginx needs to be on the same Docker network as the workload container to resolve proxy_pass http://sandbox-app-${ENV_ID}:8080/ by container name. The connect happens before the reload so the upstream is reachable the moment the route goes live.
4. Start log shipping and write the state file
nohup docker logs -f "\({CONTAINER_NAME}" >> "\){SANDBOX_ROOT}/logs/${ENV_ID}/app.log" 2>&1 &
LOG_SHIPPER_PID=$!
disown "${LOG_SHIPPER_PID}"
A docker logs -f process is backgrounded with nohup and its PID is stored in the state file. nohup matters here because when the API container (which calls this script via subprocess) exits, it would otherwise send SIGHUP to any background jobs — killing the log shipper before it ships anything. disown removes it from the shell's job table so it outlives the script.
The state file is also written atomically using python3's tempfile.mkstemp + os.replace:
{
"id": "env-a1b2c3d4e5f6a7b8",
"name": "my-feature-branch",
"created_at": "2026-05-13T18:00:00Z",
"ttl": 1800,
"status": "healthy",
"network": "sandbox-net-env-a1b2c3d4e5f6a7b8",
"container_name": "sandbox-app-env-a1b2c3d4e5f6a7b8",
"nginx_snippet": "/sandbox/nginx/conf.d/env-a1b2c3d4e5f6a7b8.conf",
"log_shipper_pid": 4291
}
Output on completion:
Created environment 'my-feature-branch' (env-a1b2c3d4e5f6a7b8)
URL: http://127.0.0.1:80/env/env-a1b2c3d4e5f6a7b8/
TTL: 1800s (cleanup daemon enforces expiry)
Destroying an environment
destroy_env.sh works through the inverse operations in a safe order:
# 1. Kill the log shipper (prevents zombie docker logs processes)
kill "${LOG_PID}"
# 2. Remove all labeled containers
docker rm -f \((docker ps -aq --filter "label=sandbox.env=\){ENV_ID}")
# 3. Disconnect nginx from the network, then remove the network
docker network disconnect -f "\({NETWORK_NAME}" "\){NGINX_CONTAINER_NAME}"
docker network rm "${NETWORK_NAME}"
# 4. Delete the nginx snippet and reload
rm -f "${NGINX_SNIPPET}"
docker exec "${NGINX_CONTAINER_NAME}" nginx -s reload
# 5. Archive logs, delete state file
mv "\({SANDBOX_ROOT}/logs/\){ENV_ID}/"* "${ARCHIVE_DIR}/"
rm -f "${STATE_PATH}"
Killing the log shipper before removing the container is important — if you remove the container first and the log shipper is still running, you'll have a zombie docker logs process spinning on a dead container ID.
After the reload, requests to /env/env-a1b2c3d4e5f6a7b8/ fall through to the default location / handler with a 200 plain text response.
TTL-based auto-cleanup

cleanup_daemon.sh runs in a loop, waking every 60 seconds. For each state file in envs/, it checks whether now > created_at + ttl using an inline Python snippet:
should_destroy="\((python3 - "\){state_file}" <<'PY'
import datetime, json, sys
from pathlib import Path
data = json.loads(Path(sys.argv[1]).read_text(encoding="utf-8"))
created = datetime.datetime.fromisoformat(data["created_at"].replace("Z", "+00:00"))
ttl = int(data["ttl"])
expires = created + datetime.timedelta(seconds=ttl)
now = datetime.datetime.now(datetime.timezone.utc)
print("true" if now > expires else "false")
PY
)"
if [[ "${should_destroy}" == "true" ]]; then
sandbox_ts_log "destroying ${ENV_ID} (past ttl)"
bash "\({SCRIPT_DIR}/destroy_env.sh" "\){ENV_ID}"
fi
Every action is timestamped and appended to logs/cleanup.log. The daemon starts at make up with nohup and its PID is saved to .cleanup.pid so make down can kill it cleanly.
Health monitoring
The health poller in monitor/health_poller.py wakes every 30 seconds, iterates over all active state files, and hits each environment's /health endpoint through nginx:
url = f"http://127.0.0.1:{port}/env/{env_id}/health"
started = time.perf_counter()
try:
with urllib.request.urlopen(request, timeout=5) as response:
status = int(response.status)
except urllib.error.HTTPError as exc:
status = int(exc.code)
except Exception as exc:
err = f"{type(exc).__name__}: {exc}"
status = None
latency_ms = int((time.perf_counter() - started) * 1000)
Each result is appended as a JSON line to logs/<ENV_ID>/health.log:
{"ts": "2026-05-13T18:12:00+00:00", "http_status": 200, "latency_ms": 4, "error": null}
A separate health_tracker.json file tracks consecutive failures per environment. After 3 consecutive failures, the poller flips the environment's status field to "degraded" atomically and emits a warning to stderr:
[2026-05-13T18:14:30+00:00] WARNING env=env-a1b2c3d4e5f6a7b8 degraded after 3 consecutive health failures
When a check succeeds again, status is reset to "healthy" and the failure counter is zeroed.
Outage simulation
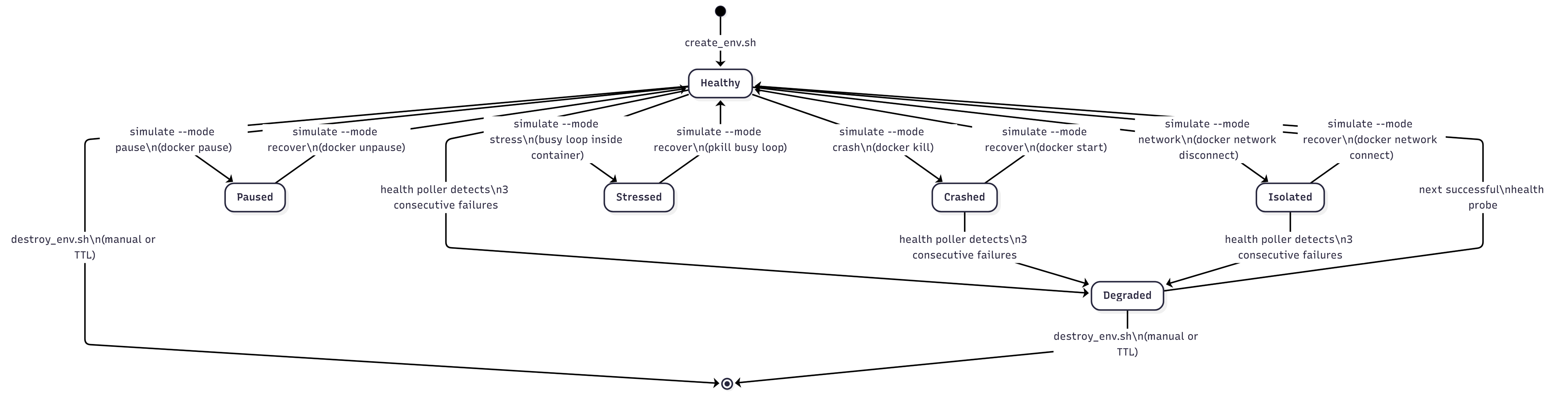
simulate_outage.sh is the chaos engineering toggle. It accepts --env and --mode and supports five modes:
| Mode | What it does |
|---|---|
crash |
docker kill — sends SIGKILL to the workload container |
pause |
docker pause — freezes all processes in the container (SIGSTOP) |
network |
docker network disconnect — severs the container from its network |
stress |
Runs a hot CPU busy-loop inside the container (no extra packages needed) |
recover |
Undoes whichever mode was previously applied |
Before doing anything, the script verifies it is targeting a workload container, not a control-plane container:
guard_container() {
local cid="$1"
local name
name="\((docker inspect --format '{{.Name}}' "\){cid}" | sed 's#^/##')"
if [[ "\({name}" == "\){NGINX_CONTAINER_NAME}" || "\({name}" == "\){API_CONTAINER_NAME}" ]]; then
echo "Refusing to simulate outage on platform container (${name})." >&2
exit 1
fi
local plat
plat="\((docker inspect --format '{{index .Config.Labels "sandbox.platform"}}' "\){cid}")"
if [[ "${plat}" == "control" ]]; then
echo "Refusing to simulate outage on control-plane container (${name})." >&2
exit 1
fi
}
The applied mode is saved to envs/.sim/<ENV_ID> so recover knows what to undo. The crash recovery path has an extra detail: since docker kill terminates the container, the docker logs -f shipper also dies. Recovery restarts the container, spawns a new log shipper, and patches the stored PID in the state file atomically.
crash)
docker start "${cid}"
nohup docker logs -f "\({cid}" >> "\){APP_LOG}" 2>&1 &
NEW_LOG_PID=$!
disown "${NEW_LOG_PID}"
# atomic patch of log_shipper_pid in state file
...
Because each environment's container is the only thing behind its proxy_pass, stopping a container without touching nginx produces a clean 502 Bad Gateway at the edge — which is exactly the signal your monitoring stack should catch.
The control API
platform/api.py is a FastAPI application that wraps the shell scripts. It exposes six endpoints:
POST /envs → create env (body: {name, ttl})
GET /envs → list all active envs with TTL remaining
DELETE /envs/{id} → destroy env
GET /envs/{id}/logs → last 100 lines of app.log
GET /envs/{id}/health → last 10 health check records
POST /envs/{id}/outage → trigger simulation (body: {mode})
Each endpoint either reads state files directly (for reads) or calls the corresponding shell script via subprocess.run:
def _run_script(rel: str, *args: str, timeout: int = 600) -> str:
script = ROOT / "platform" / rel
result = subprocess.run(
["bash", str(script), *[str(a) for a in args]],
cwd=str(ROOT),
env={**os.environ, "SANDBOX_ROOT": str(ROOT)},
capture_output=True,
text=True,
timeout=timeout,
check=False,
)
if result.returncode != 0:
detail = (result.stderr or result.stdout or "").strip()
raise HTTPException(status_code=500, detail=detail)
return (result.stdout or "").strip()
The API container mounts the Docker socket (/var/run/docker.sock) so the shell scripts running inside it can call docker commands against the host daemon. The entire repo is also bind-mounted into the container at /sandbox so script paths, state files, and log directories are all consistent.
The GET /envs endpoint computes TTL remaining live on each request:
def _ttl_remaining_seconds(data: dict) -> int:
created = datetime.fromisoformat(str(data["created_at"]).replace("Z", "+00:00"))
expires = created + timedelta(seconds=int(data["ttl"]))
now = datetime.now(timezone.utc)
return max(0, int((expires - now).total_seconds()))
Interactive docs are at http://127.0.0.1:9090/docs once the stack is up.
Makefile ergonomics
Every operation has a make target so the platform is scriptable and human-friendly at the same time:
make up # start nginx + api, launch daemon + health poller
make down # stop everything, destroy all active envs
make create # interactive: prompts for name + TTL
make destroy ENV=env-a1b2c3d4 # destroy specific env
make logs ENV=env-a1b2c3d4 # tail app.log (falls back to archived logs)
make health # print status table for all envs
make simulate ENV=... MODE=... # run outage simulation
make clean # wipe all state, logs, and generated nginx snippets
make up also handles idempotency: it checks whether the daemon and health poller are already running before starting new instances.
What I learned building this
Atomicity shows up everywhere. Three separate layers of the system use the write-to-temp-then-rename pattern: the nginx snippet writer in create_env.sh, the state file writer in common.sh, and the health tracker updater in health_poller.py. The pattern costs nothing and eliminates an entire class of race conditions where a reader sees a partial file.
Labels are your namespace. Using sandbox.env=<ID> and sandbox.role=workload labels on every container means destroy_env.sh can find exactly what it needs with docker ps --filter without hardcoding any names. It also makes the control-plane guard trivial to implement — just check the label.
nohup + disown for background processes launched by subprocess. Running docker logs -f ... & in a script called by a Python subprocess sounds simple but produces zombie log shippers without nohup. The subprocess parent exits, bash sends SIGHUP to background jobs, and the shipper dies before writing anything. nohup suppresses the signal; disown removes the job from the table so it truly outlives the shell.
The bootstrap stub is not optional. The nginx glob edge case ([emerg] open()... No such file or directory) is easy to miss in development because you always have at least one env running. It only surfaces on a clean boot with zero environments, which is exactly when you need the platform to start reliably.
nginx -s reload is not instantaneous but it is safe. New workers pick up the fresh config; old workers finish draining in-flight requests. Under low load this takes milliseconds. Under heavy load you'll see a brief overlap — which is fine, because the old route is still being served until the drain completes. The new route is not yet live during that window, but nothing breaks.
When this pattern fits (and when it doesn't)
Good fit:
- Routes are created/destroyed by external events — deployments, tenant provisioning, CI pipelines
- You can't afford connection drops on reload
- The route set is unbounded or changes frequently enough that hardcoding into a master config isn't maintainable
Poor fit:
- Sub-second reconfiguration at very high frequency (nginx reload takes ~100ms to drain workers; for that latency class, look at OpenResty/Lua or Envoy xDS)
- Environments that need to survive restarts with complex state beyond what a JSON file can hold
Running it
git clone https://github.com/Trojanhorse7/devops-sandbox
cd devops-sandbox
make up
# create an environment
make create
# → Environment name: demo
# → TTL seconds [1800]: 300
# → URL: http://127.0.0.1:80/env/env-a1b2c3d4e5f6a7b8/
# check health
make health
# simulate a crash
make simulate ENV=env-a1b2c3d4e5f6a7b8 MODE=crash
# health monitor catches it within 90 seconds, status → degraded
# recover
make simulate ENV=env-a1b2c3d4e5f6a7b8 MODE=recover
# or let the TTL expire — cleanup daemon destroys it automatically
Full source: github.com/Trojanhorse7/devops-sandbox